
How AI Extracts Property Information from Real Estate Documents

Where business growth depends on data-driven decisions, nothing hampers your progress more than inaccurate, unstructured and messy data. Data cleansing identifies and corrects your records, ensuring the complete accuracy and reliability of your data.
Table of Contents
If your decisions have been impacting customer trust, compliance, and revenue growth despite having the best team and infrastructure, then it is time to audit your data. Most underestimated yet most damaging dirty data silently kills your business growth.
Here are a few glaring stats that prove data quality cannot be ignored any more.
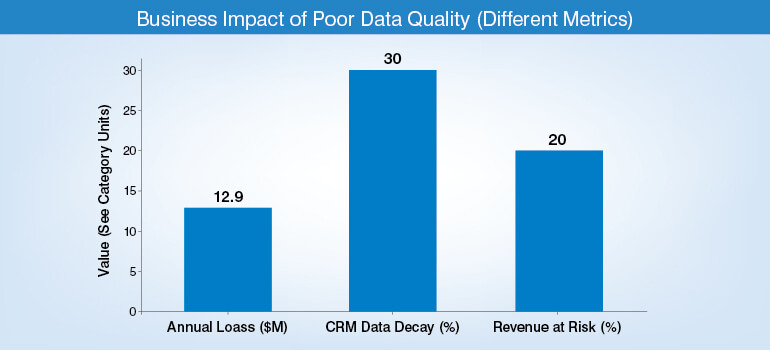
Transforming business data quality acts as a foundational capability that supports CRM accuracy. Even the most advanced AI and analytical systems deliver misleading insights if the records are outdated and inaccurate. Duplicate records and missing fields also reduce operational efficiency.
B2B data cleansing strategies must be implemented to support CRM accuracy. Here is in this blog, we discuss 10 real-world data cleansing examples that organisations use to transform unreliable datasets into reliable business assets.
It is not about theory, and these data cleansing examples will help you understand how these practices improve compliance, performance and customer outcomes. Data cleansing services are a must for every organisation.
Struggling with inconsistent or unreliable data?
Data cleansing is the process of identifying and correcting inaccurate, incomplete, duplicate, or outdated data within a dataset. It ensures that business data remains consistent, reliable, and usable for decision-making.
The process is not just about fixing errors; it also plays an important role in improving analytics accuracy, strengthening customer insights, and ensuring compliance. Clean data improves the performance of AI/ML models and automation systems. Even the most advanced systems can deliver flawed outcomes if the underlying data is not clean.
Data cleansing is critical because even small errors can lead to big mistakes. Wrong data means wrong decisions. Clean data builds trust. It improves reporting, sharpens analytics, and strengthens customer insights. For enterprises handling massive volumes, it ensures consistency, compliance, and efficiency. It also prevents costly rework and operational delays.
Clean data directly impacts performance in measurable ways. Operational errors get reduced drastically, decision making gets faster and more accurate, driving higher conversions. The result is better efficiency, stronger ROI, and more confident, data-driven growth.
Here, we explore the real impact of data cleansing solutions across industries through tangible business outcomes. Implementing data cleansing in your business often results in improved operational efficiency and informed and correct decision-making, resulting in measurable outcomes. Here are the 10 data cleansing examples.
Duplicate records contaminate between 10-30% of business records across most organizations. Duplicates often creep into the CRM through multiple sources, which are often unavoidable.
The same customer fills out the website form more than once, using different names or just initials. Sometimes duplicates creep in because of data entry errors or data imported from multiple sources.
Duplicate records often result in sending the same sales pitch to a single customer twice or multiple representatives contacting the same person, leading to complete mistrust in the CRM and hitting your credibility.
The data cleansing process here would start by identifying duplicates through data quality workflows or matching rules. Overlapping fields are merged to create a single customer view. Tools and techniques like fuzzy matching algorithms detect near-duplicate records while deduplication rules match emails, phone numbers and customer IDs.
Once the data gets deduplicated and cleaned, the sales teams work with reliable customer profiles, improving targeting and better outcomes.
Misaligned data formats can damage your marketing campaigns in many ways, especially when your sales pitch depends on personalization, segmentation, and automation. For systems to interpret and exchange data accurately, the formats used for dates, phone numbers, and addresses all need to align. As businesses scale digital operations, data standardization has become a major focus, with global spending on related tools crossing $12 billion and 68% of IT leaders prioritizing standardization for cloud scalability.
Without proper validation rules, data collected from multiple sources and in different data formats gets totally mixed up and misaligned. A simple example could be a format difference like (DD/MM/YYYY vs MM/DD/YYYY). Such a difference in formats may fail segmentation filters, and your campaign can reach the wrong audience. Even automation tools that depend on standardized fields may not function properly.
Data cleansing applies data standardization rules for dates, phone numbers and addresses and ETL pipelines for format normalization. Regex-based validation, address validation and normalization APIs and other data quality tools help standardize data formats.

Customer records often get outdated due to multiple reasons and using such contact details, your campaigns either don’t reach the right audience or may land in the junk mail. There are multiple reasons for this to happen.
Customers often change their contact details, you don’t remove the old leads from the CRM, inactive subscribers are not removed from the system and so on. If you keep growing your database without any kind of data cleansing, you end up wasting the time of your sales team and missing out on opportunities.
There is lower email deliverability, increased bounce rates, wasted dollars invested in campaign budget and reduced ROI.
When you apply data cleansing methods like email validation and verification tools, regular database audits, data cleansing workflows, and automated inactivity rules, your team improves with targeted marketing, driving higher engagement.

Typos in name, address may come across as minor errors, but they create inconsistencies making records difficult to search and match across systems.
Spelling errors are very easy to creep into your system and need immediate correction. It happens often during manual data entry, OCR or data migration errors or if you don’t have any set validation rules for text fields.
Once mis-spellings creep into your system you can’t find records, duplicate records are created, reports and dashboards show fragmented data and your communication gets unprofessional.
What you need to do is apply various tools and techniques like spell-check, data profiling tools that detect anomalies and reference dictionaries and validation rules.
Correcting misspellings improved record searchability, reduced duplicate entries, and ensured more professional customer communication across systems.
Clean data powers better decisions.

Incorrect contact details break the communication chain between businesses and customers, leading to missed opportunities, wasted effort, and reduced trust. Incorrect contact details break the communication chain between businesses and customers, leading to missed opportunities, wasted effort, and reduced trust. A recent Salesforce study found that nearly 20% of customer records become unusable due to inaccurate, outdated, or duplicate information.
This issue cannot be avoided, as often customers themselves provide incorrect details during form submission. Also, contact information changes over time and if the database is not validated or updated regularly, it leads to faulty data. Data is also imported from multiple sources and integrated into the database without any verification.
This leads to failed email deliveries, connecting to wrong people or not getting connected at all. Calling wrong people often leads to lost trust and low engagement.
Data cleansing can easily help solve this problem. Phone number validation APIs, email validation and verification tools, address validation and enrichment services along with periodic audits, can keep your contact details completely updated all the time. Real time update algorithms can also be applied to keep the database accurate at any point in time.
Just accuracy cannot make the database complete and effective. A dataset must have other attributes like location, industry, product specifications or customer segmentation to make your database complete.
It often happens that certain optional fields are left blank during data collection process and even sometimes during manual entry fields not marked mandatory are skipped. Also, due to storage shortage limited attributes get uploaded into the system. And it also happens that attributes or information needed to complete the database are not available.
This impacts your business. You end up doing incomplete segmentation, inaccurate analytics, poor forecasting and ultimately reduced efficiency. Your campaigns are not targeted getting you poor market response.
Data cleansing of hospitality records improved the CRM accuracy for the database.
Data is enriched using data enrichment APIs and third-party datasets. First one applies business rules that detect relevant missing values. Then, through reference data mapping missing values are inserted and validated. Checks are done for CRM and PIM data completeness so that no values are missed. ETL workflows are used for attribute normalization.
This leads to improved datasets that enable better and data backed business decisions across departments and organization.
If entity names are not normalized and they appear in different naming variations, say spelling differences or one place it appears in full form and other places in abbreviation, it can create confusion. You will find one customer listed under ‘XYZ limited’ and under ‘XYZ Ltd.’. The resulting fragmented records across systems will result in mismanaged campaigns.
The problems often happen due to manual entry where inconsistent naming conventions are used and a lack of master reference data or rules. This impacts business in multiple ways. You end up generating inconsistent and unreliable reports with duplicate entries. There is reduced trust in reports and analysts waste time restructuring names manually.
Data cleansing techniques like name matching algorithms, reference dictionaries, along with master data management systems, help with standardizing naming conventions. ETL workflows also help with entity normalization.
By applying such techniques to normalize entity names organizations improved operations and confidence in business intelligence.

Sometimes, irrelevant fields get added to your database, causing a lot of noise and unnecessary complications. It hinders the job of analysts and even reduces operational efficiency and the business also suffers.
Due to a lack of periodic audits and data model governance plenty of redundant data sits on your database making it cluttered and there is a total lack of clarity. Often, during system upgrades legacy fields are left behind that also add to this noise.
Due to cluttered analytical dashboards, business teams face difficulty using the data. It leads to slowed down reporting and query performance. Also, it results in confusion about which fields to use for analyzing the data.
The solution lies in using data model audits and schema reviews. You need to have a data-governance policies for schema control and field-usage analysis in CRM, ERP or BI systems. Once you remove the redundant fields you have clarity leading to reduced processing time for analytics and automated workflows.
Ready to turn messy data into trusted assets?

This may look simple but has huge implications for your business growth. Inaccurate segmentation leads to bad analytics and reporting. This happens when your industries, transaction records or products are not put in correct categories.
Often due to poorly defined taxonomy or incorrect tagging during manual data entry the data gets classified wrongly. This also happens due to inconsistent category definitions across teams or when classification rules are not updated over time.
This incorrect classification leads to targeting the wrong audience during campaigns and poor recommendation engine performance. You cannot personalize your campaigns, resulting in poor engagement. Your analytics also go wrong and dashboards no longer remain reliable.
To correct this data profiling tools are used that identify anomalies in the first place. Then rule-based classification workflows and machine learning assisted reclassification are used. Taxonomy validation and domain expert validation of categories help clear this mess.
Reclassifying records in your database in appropriate and relevant categories improves your targeting accuracy, reliability and personalization.

Customer notes, feedback, comments or product descriptions are very important for analysis and future course of action by the organizations. But they are often stored as unstructured free text that is difficult to trace and understand. So, you miss good data that could have proved beneficial for your business growth.
This problem is almost unavoidable because customers often write in different styles, descriptions entered without any standard format or legacy systems storing text without metadata. Manual comments stored without any tagging or structure get lost easily and make no sense.
Dirty data makes organizations miss out on valuable insights hidden in text data. It makes the search functionality also unreliable. You cannot analyze customer feedback effectively and AI initiatives become harder to implement.
Multiple data cleansing methods help solve this issue. Text parsing, NLP tagging, structured metadata mapping and use of standard terminology dictionaries are some of the methods that prove effective here. This improves operational visibility across customer support, product data, and internal reporting systems.
Enterprises face several challenges in maintaining clean, reliable data at scale:
These examples clearly point towards the relevance and importance of clean data for any organization. Data cleansing is not a one-time process. How often you should do this activity or should this process be integrated into your system depends on many factors. Based on you need, you may opt for the structure best suited to you.
It will depend on your business need, volume, data complexity and sensitivity. But it has to be an ongoing process.
Here are a few suggestions.
Data cleaning is not about technically correcting your dataset, it is about transforming your data into more relevant, user-friendly, accurate driving operational efficiency and ROI. The examples we have discussed above clearly point towards the need to implement and integrate a data cleansing process into your systems. This is no more an option; it is non-negotiable if you wish to stay alive in the competition and grow. It is an ongoing process and based on your business needs, you must decide on the frequency. As your growth gets directly dependent on data-driven decisions, clean and structured and enriched data becomes a strategic priority.

What’s next? Message us a brief description of your project.
Our experts will review and get back to you within one business day with free consultation for successful implementation.
Disclaimer:
HitechDigital Solutions LLP and Hitech BPO will never ask for money or commission to offer jobs or projects. In the event you are contacted by any person with job offer in our companies, please reach out to us at info@hitechbpo.com


