
How AI Extracts Property Information from Real Estate Documents

Demand for AI adoption and the need for high-quality text annotation continues to grow. Mislabeled text, unbalanced training data, and bias significantly impacts the outcomes of NLP models. This increases the importance of accurately labeling text of digital files or documents.
Table of Contents
Text annotation plays a crucial role in natural language processing (NLP) applications, such as chatbots, virtual assistants, search engines, and machine translation, as it helps AI models understand human language and communication more effectively.
The global NLP market generated turnovers of over $12 billion in 2020, and it is predicted that the market will grow at a compound annual growth rate (CAGR) of about 25% from 2021 to 2025, reaching revenues of over $43 billion. This growth highlights the increasing demand for high-quality text annotation services.
Inaccuracies in the text annotation of training data can make AI models fail to perform in real-world applications. According to a Gartner report, injecting 8% of erroneous training data can decrease AI’s accuracy by 75%.
Text annotation in machine learning is the process of assigning labels to a text document or to different elements of its content to identify the characteristics of sentences. It involves tagging language data in text or audio recordings with additional information or metadata to define the characteristics of sentences, such as highlighting parts of speech, grammar, syntax, keywords, phrases, emotions, sarcasm, sentiments, and more.
Text labeling, also known as text annotation or tagging, is the process of assigning labels or categories to text data to make it more understandable and usable for various natural language processing (NLP) tasks.
It is important to note that the terms “text annotation” and “text labeling” are often used interchangeably, as they both involve adding information to text data to train AI/ML models. However, text annotation is a broader concept that encompasses a wider range of activities, while text labeling is a specific subtask within text annotation.
| Text Annotation | Text Labeling | |
|---|---|---|
| Definition | Text Annotation Text annotation is a broader term encompassing adding additional information, metadata, or context to a text. | Text Labeling Text labeling, also known as text tagging, is the process of assigning labels or categories to text data to make it more understandable and usable for various NLP tasks. |
| Purpose | Text Annotation Text annotation helps train AI/ML models to understand the context, emotions, and relationships between different parts of the text. | Text Labeling Text labeling is used for supervised machine learning tasks where labeled data is required to train and evaluate models, enabling them to make predictions, extract information, or perform other NLP tasks based on the labeled information. |
| Examples | Text Annotation Adding comments or explanations to text for clarity or to provide additional context, associating multimedia elements like images, videos, or links with text passages. | Text Labeling Text classification, named entity recognition, keyphrase extraction, and sentiment analysis. |
| Methodology | Text Annotation Text annotation can be done manually or with automated tools, depending on the specific task. | Text Labeling Text labeling can also be done manually or with automated tools, but it is a specific subtask within text annotation. |
Text annotation is used across various industries to identify errors and improve business outcomes. Here are five examples of how different industries use text annotation to achieve better results:
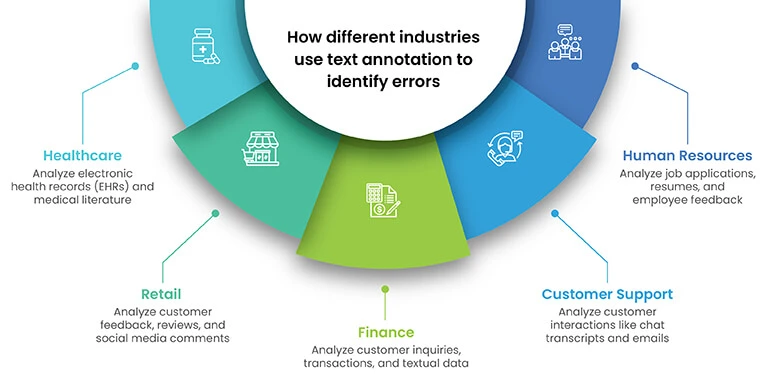
1. Healthcare: Text annotation is used to analyze electronic health records (EHRs) and medical literature, helping healthcare professionals identify patterns, trends, and correlations in patient data. For instance, a study found that using natural language processing (NLP) to analyze EHRs could predict hospital readmissions with 71.2% accuracy.
2. Retail: Text annotation is employed to analyze customer feedback, reviews, and social media comments, enabling retailers to identify trends, preferences, and areas for improvement. One study by IBM reported that 62% of retail respondents claimed that insights provided by analytics and information gave them a competitive advantage.
3. Finance: Financial institutions use text annotation to analyze customer inquiries, transactions, and other textual data to detect fraud, improve customer service, and streamline operations. For example, Bank of America uses natural language processing and predictive analytics to create a virtual assistant called Erica, which helps customers view information on upcoming bills or transaction histories.
4. Customer Support: Text annotation is used to analyze customer support interactions, such as chat transcripts and emails, to identify common issues, trends, and areas for improvement. By understanding customer sentiments and needs, businesses can enhance their support services and increase customer satisfaction.
5. Human Resources: Text annotation is employed to analyze job applications, resumes, and employee feedback, helping HR professionals identify patterns, trends, and potential issues. For example, text annotation can be used to analyze employee feedback to identify areas of concern, such as workplace culture or management issues, and take appropriate actions to address them.
By leveraging text annotation, these industries can gain valuable insights from unstructured data, leading to improved decision-making, enhanced customer experiences, and better overall business outcomes.
Text annotation tasks consist of appending notes to text based on requirements and use cases, such as annotating words, phrases, sentences, etc., and labeling them (e.g., proper names, sentiment, intention). Text annotation in machine learning is the process of labeling text with metadata to assist machine learning models in understanding and processing human language. High-quality datasets are crucial in AI training, as they directly impact the performance, accuracy, and reliability of AI models.
AI’s ability to label keywords, phrases, or sentences is a crucial aspect of natural language processing (NLP) and text annotation. It helps AI models understand and process human language more effectively. AI models can analyze various linguistic aspects, such as semantics, syntax, pragmatics, and morphology, and then apply this knowledge to perform the desired tasks.
One example of this is keyword extraction, which pulls the most important words from the text, making it useful for search engine optimization.
Machine learning algorithms, such as those used in NLP, require massive amounts of labeled data for training and identifying relevant correlations. Assembling this kind of big data set is one of the main hurdles to natural language processing.
However, recent advancements in AI and machine learning have led to the development of more efficient and accurate text annotation tools. A report by The Everest Group found that pace of AI adoption has increased significantly by 32% in the last two years, making data labeling more important than ever.
Optical Character Recognition (OCR) is a technology that converts images of text, such as scanned documents or photographs, into machine-readable text format. OCR plays an essential role in text annotation, as it enables the conversion of printed or handwritten text into a digital format that can be further processed and analyzed by AI and ML models.
In the context of text annotation, OCR helps create machine-readable text from images or scanned documents, which can then be annotated with metadata, such as labels for keywords, phrases, or sentences. This process is crucial for preparing data for AI and ML training, especially in natural language processing (NLP) applications.
OCR technology has evolved significantly over the years, with advancements in AI and machine learning contributing to improved accuracy and efficiency in document analysis. AI-powered OCR systems use natural language processing, machine learning, and deep learning technologies to provide more accurate text recognition and extraction.
This enhanced capability allows OCR to be used in a broader range of contexts and applications, such as data extraction from invoices, receipts, reports, and more.
Assigning labels to digital files or documents and their content is a crucial step in preparing data for AI and ML training, especially in natural language processing (NLP) applications.
A report by the market research firm Cognilytica estimated that the data labeling market will more than double in the five years starting in 2019, expanding from $1.5 billion to over $3 billion. This growth highlights the increasing need for high-quality labeled data in various industries and applications.
Labeling digital files or documents can involve annotating and categorizing various types of data, such as medical images, clinical texts, or other data types, to extract meaningful insights and facilitate various applications in healthcare. In computer vision, data labeling involves adding tags to raw data, such as images and videos, with each tag representing an object class associated with the data.
AI and ML companies confront multiple challenges in text annotation processes. These include ensuring data quality, handling large datasets efficiently, managing annotator biases, securing sensitive data, and scaling up as data grows. Addressing these concerns is critical to achieve precise model training and robust AI outcomes.

This happens when a word, phrase, or sentence can have multiple interpretations. This can lead to inconsistencies and errors in the annotation process, as different annotators may interpret the same text differently.
For example, the phrase “I saw the man with the telescope” can be interpreted in two ways: either the speaker saw a man who had a telescope, or the speaker used a telescope to see the man. Resolving such ambiguities is crucial for training accurate and reliable machine learning models.
This refers to the presence of personal opinions, emotions, or evaluations in the text. Annotating subjective language can be challenging because different annotators may have different interpretations of the same text, leading to disagreements and inconsistencies in the annotations.
For instance, annotating sentiment in customer reviews may result in different annotators labeling the same review as positive, neutral, or negative based on their own understanding and perception of the text.
It is essential for accurate text annotation, as the meaning of words and phrases often depends on the context in which they are used. Annotators must consider the surrounding text and the overall meaning of the passage to accurately label and categorize the data.
For example, the word “bank” can refer to a financial institution or the side of a river, depending on the context. Failing to consider the context may lead to incorrect annotations and negatively impact the performance of machine learning models.
It poses a challenge in text annotation, as annotators must be proficient in multiple languages to accurately label and categorize data in different languages. This can be particularly challenging when dealing with less common languages or dialects, as finding annotators with the required expertise may be difficult. Additionally, language diversity can lead to inconsistencies in the annotation process, as different annotators may have varying levels of proficiency in a given language.
This process of annotating large volumes of data is time consuming and resource intensive, posing a significant challenge in text annotation. Research shows that more than 80% of AI project time is spent managing data, including collecting, aggregating, cleaning, and labeling it. As the volume of data increases, the demand for data annotators also grows, making it challenging for companies to scale their annotation efforts efficiently.
It is a major hurdle for companies, as hiring and training annotators, as well as investing in annotation tools and technologies, can be expensive. The global data labeling market is expected to reach a value of $13 billion by 2030, highlighting the significant investment required for high-quality data annotation. Balancing the need for accurate and consistent annotations with the cost of annotation services is a critical challenge for companies looking to implement AI and machine learning solutions.
Text annotation involves assigning labels to text data, which is crucial for training machine learning models and natural language processing tasks. Common types of text annotation include entity annotation, sentiment analysis, and text classification.
The global NLP market, which relies heavily on text annotation, generated over $12 billion in 2020 and is predicted to grow at a CAGR of about 25% from 2021 to 2025, reaching revenues of over $43 billion. This growth highlights the significance of text annotation service providers in the AI and ML industry.
Offering text annotation services to AI and ML companies and platforms for more than two decades now, we at Hitech BPO have had the privilege of working on all types of text annotation. Let me walk you through the diverse types of text annotations:
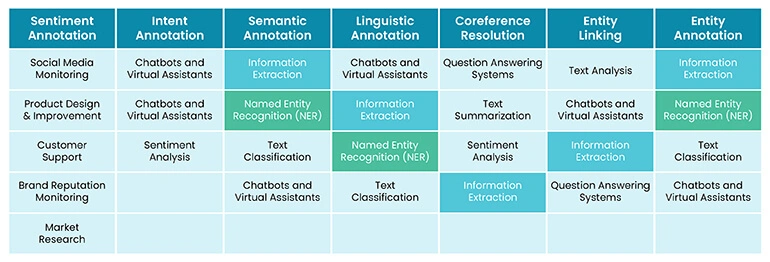
Sentiment annotation is the process of evaluating and labeling the emotions, attitudes, and opinions expressed in a text, such as a review, a tweet, or a social media post. It is commonly used in sentiment analysis, which is a natural language processing (NLP) technique that determines whether a piece of text is positive, negative, or neutral. The purpose of sentiment annotation is to provide labeled data for training and evaluating machine learning models, which can then be used to analyze and understand the sentiments behind various texts.
Real-life applications of sentiment annotation and sentiment analysis include:
Intent annotation is the process of analyzing and labeling text to capture the purpose or goal behind it. In this type of annotation, annotators assign labels to text segments representing specific user intentions, such as asking for information, requesting something, or expressing a preference. Intent annotation is particularly valuable in developing AI-powered chatbots and virtual assistants, as it helps these models understand user inputs and provide appropriate responses or perform desired actions.
The purpose of intent annotation is to create datasets that can train machine learning models to determine what the writer of the text wants. By annotating each message with a specific intent, AI models can better understand the true purpose of text messages and respond accordingly.
Real-life applications of intent annotation include:
The global data annotation and labeling market is projected to grow from USD 0.8 billion in 2022 to USD 3.6 billion by 2027, at a CAGR of 33.2%. This growth highlights the increasing demand for high-quality intent annotation and its importance in various industries and applications.
Semantic annotation is the process of tagging documents or unstructured content with metadata about concepts such as people, places, organizations, products, or topics relevant to the content. The result of the semantic annotation process is metadata, which describes the document via references to concepts and entities mentioned in the text or relevant to it.
These references link the content to formal descriptions of these concepts in a knowledge graph. Semantic annotation enriches content with machine-processable information by linking background information to the extracted concepts, which are unambiguously defined and related to each other within and outside the content. This process turns the content into a more manageable data source.
The purpose of semantic annotation is to improve the discoverability, interoperability, and reusability of data by providing precise definitions of concepts and clarifying the relationships among concepts in a machine-readable way.
Real-life applications of semantic annotation include:
Linguistic annotation is the process of adding descriptive or analytic notations to raw language data, such as text, speech, or images. These notations can include transcriptions of various sorts (from phonetic features to discourse structures), part-of-speech and sense tagging, syntactic analysis, named entity identification, co-reference annotation, and more.
The purpose of linguistic annotation is to provide additional information about the text, which can be used for various natural language processing (NLP) tasks, such as machine learning, sentiment analysis, or text classification.
Real-life applications of linguistic annotation include:
Coreference resolution is a natural language processing (NLP) task that involves identifying and linking linguistic expressions (called mentions) in a given text that refer to the same real-world entity.
The goal is to group these mentions into clusters, which helps resolve ambiguity and provides a clearer understanding of the text. By resolving coreferences, the text becomes less ambiguous and more easily understood by computers. Coreference resolution is essential for various NLP tasks, such as:
Real-life applications of coreference resolution include:
It is worth noting that this has been an active area of research in NLP for many years, with numerous datasets, benchmarks, and models available for evaluation and comparison. The continuous development of new techniques and models, such as the introduction of Transformer-based models, has led to significant improvements in coreference resolution performance.
Entity linking is the process of connecting entity mentions in text to their corresponding entries on a knowledge base, such as Wikidata or Wikipedia. This process helps to disambiguate entities with similar names and provides additional context and information about the mentioned entities.
The purpose of entity linking is to improve information extraction, retrieval, and knowledge base population by linking unstructured text data to structured knowledge repositories.
Real-life applications of entity linking include:
Entity annotation is the process of labeling named entities within sections or pages of text. Named entities can include people, organizations, products, locations, and other categories. The purpose of entity annotation is to create datasets that can train machine learning models to understand the structure and meaning behind a piece of text, which is a critical pre-processing step for many other NLP tasks.
Real-life applications of entity annotation include:
The global data annotation tools market was valued at USD 1,186.9 million in 2021 and is projected to reach USD 13,287.9 million by 2030. This growth highlights the increasing demand for high-quality entity annotation and its importance in various industries and applications.
Elevate your project with our expert text annotation services.
The difference between entity annotation and entity linking in NLP lies in their respective goals and processes. Entity annotation is the process of labeling named entities within sections or pages of text, such as people, organizations, products, locations, and other categories. This process helps to create datasets that can train machine learning models to understand the structure and meaning behind a piece of text.
On the other hand, entity linking is the process of connecting entity mentions in text to their corresponding entries on a knowledge base, such as Wikidata or Wikipedia.
This process helps disambiguate entities with similar names and provides additional context and information about the mentioned entities. Entity linking improves information extraction, retrieval, and knowledge base population by linking unstructured text data to structured knowledge repositories.
There are three main types of text annotation techniques: manual annotation, semiautomatic annotation, and automatic annotation. However, using any of these or a combination of more than one – purely depends on your text annotation project needs.

First, let’s check out the definitions, advantages, and limitations of all these types of annotation techniques:
Manual text annotation is the process of adding information, labels, or tags to a text by human experts or domain specialists based on predefined standards, rules, or schemas. This additional information helps in understanding, analyzing, and processing the text for various natural language processing (NLP) and machine learning tasks.
Purpose of manual text annotation:
Advantages of manual text annotation:
Disadvantages of manual text annotation:
Semi-automatic text annotation is a process that combines human expertise and automated tools to add information, labels, or tags to a text. This approach aims to strike a balance between the accuracy of manual annotation and the efficiency of automatic annotation.
In semi-automatic text annotation, annotators are assisted by algorithms that suggest annotations based on prior annotations or existing datasets.
Purpose of semi-automatic text annotation:
Advantages of semi-automatic text annotation:
Disadvantages of semi-automatic text annotation:
Automatic text annotation is the process of using algorithms and machine learning models to add information, labels, or tags to a text without human intervention. This approach aims to improve the efficiency of the annotation process by reducing the time and effort required for manual annotation.
Purpose of automatic text annotation is to:
Advantages of automatic text annotation include:
Disadvantages of automatic text annotation are:
Leverage text annotation techniques for your data with our expertise.
Text annotation tools are essential for preparing data for AI and ML training, particularly in natural language processing (NLP) applications. These tools can be broadly categorized into open source and commercial offerings. Open-source text annotation tools are freely available and can be customized according to user needs. They are popular among startups and academic projects due to their cost-effectiveness.
On the other hand, commercial text annotation tools offer more advanced features and support, making them suitable for large-scale projects and enterprise applications.
spaCy: spaCy is an open-source library for advanced natural language processing in Python. It is designed specifically for production use and helps in building applications that process and understand large volumes of text. While spaCy itself is not a text annotation tool, it can be used in combination with other tools like Prodigy or Doccano for text annotation tasks.
NLTK (Natural Language Toolkit): NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources, along with a suite of text-processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning. Like spaCy, NLTK is not a text annotation tool, but can be used in combination with other tools for text annotation tasks.
Stanford CoreNLP: Stanford CoreNLP is a Java-based toolkit for various natural language processing tasks, including part-of-speech tagging, named entity recognition, parsing, and coreference resolution.
While it is not a standalone text annotation tool, it can be used as a backend for other annotation tools or integrated into custom annotation pipelines.
GATE (General Architecture for Text Engineering): GATE is an open-source software toolkit capable of solving almost any text-processing problem. It has a mature, extensive ecosystem of components for diverse language processing tasks, including text annotation, information extraction, and semantic annotation.
Apache OpenNLP: Apache OpenNLP is a machine learning-based toolkit for processing natural language text. It supports common NLP tasks, such as tokenization, sentence segmentation, part-of-speech tagging, entity extraction, chunking, parsing, and coreference resolution. Like other NLP libraries, it can be used in combination with other tools for text annotation tasks.
UIMA (Unstructured Information Management Architecture): UIMA is an open-source framework for building applications that analyze unstructured information, such as text, audio, and video. It provides a common platform for developing, integrating, and deploying NLP components and can be used in combination with other tools for text annotation tasks.
Amazon Comprehend: This is a natural language processing (NLP) service that uses machine learning to extract insights from text. It recognizes entities, key phrases, language, sentiments, and other common elements in a document.
Amazon Comprehend provides features such as Custom Entity Recognition, Custom Classification, Key phrase Extraction, Sentiment Analysis, Entity Recognition, and more APIs, allowing easy integration of NLP into applications.
Google Cloud Natural Language API: It provides natural language understanding technologies to developers, including sentiment analysis, entity analysis, entity sentiment analysis, content classification, and syntax analysis. This API is part of the larger Cloud Machine Learning API family and empowers developers to apply natural language understanding (NLU) to their applications.
Microsoft Azure Text Analytics: It is a collection of features from AI Language that mines insights from unstructured text using NLP. It provides advanced natural language processing over raw text and has four primary functions: Sentiment Analysis, Key Phrase Extraction, Language Detection, and Named Entity Recognition.
IBM Watson Natural Language Understanding: It uses deep learning to extract meaning and metadata from unstructured text data. It provides text analytics to extract categories, concepts, emotions, entities, keywords, relations, and sentiment from text. It is an offering within the IBM Cloud and can be integrated into applications using REST APIs and SDKs.
MeaningCloud: It is a text analytics platform that provides services such as sentiment analysis, topic extraction, entity recognition, and classification. It supports multiple languages and can be integrated into applications using APIs and SDKs.
Rosette Text Analytics: The text analytics platform that offers services such as entity extraction, sentiment analysis, relationship extraction, and language identification. It supports multiple languages and can be integrated into applications using APIs and SDKs.
Machine learning algorithms, particularly supervised learning models, are trained on labeled datasets to automatically recognize patterns in text. These patterns can include named entities, sentiments, parts of speech, and more. Once trained, these models can automatically annotate unstructured text data, saving time and effort compared to manual annotation.
Use of machine learning in text annotation
1. Training the machine learning model:
2. Testing and validation:
3. Automated annotation:
Automated text annotation tools and techniques can help accelerate the annotation process and improve the quality of the annotated data. Some popular tools for automating text annotation include natural language processing (NLP) libraries, computer vision algorithms, and AI-assisted annotation platforms like Labelbox, Prodigy, and V7 Labs. These tools can help in automating tasks such as entity annotation, sentiment annotation, intent annotation, and more.
Data preparation – Data preparation is the first step in the text annotation process. It involves collecting and organizing the raw data that will be used for annotation. This may include gathering text from various sources, such as websites, social media, or internal documents, and organizing it into a structured format that can be easily annotated.
Research shows that more than 80% of AI project time is spent managing data, including collecting, aggregating, cleaning, and labeling it.
Data cleaning – Data cleaning is the process of removing noise, inconsistencies, and irrelevant information from the text data. This may involve:
Data normalization – Data normalization is the process of converting text into a standardized format that can be easily understood by machine learning algorithms. This may involve:
Data augmentation – Data augmentation is the process of creating new data points by applying various transformations to the existing data. In NLP, this can involve:
Annotation guidelines – Annotation guidelines are a set of rules and suggestions that act as a reference guide for annotators. They should:
Creating annotation guidelines – AI and ML companies should craft annotation guidelines meticulously. Start by understanding the project’s specific objectives. Offer clear definitions, use illustrative examples, ensure consistent standards, periodically update based on feedback, and train annotators thoroughly. This ensures high-quality data, essential for reliable model performance.
Developing annotation guidelines – It is an iterative process that requires strategic planning and involves:
Training annotators – It is crucial for ensuring high-quality annotations, and includes:
Quality Control – It is essential for maintaining the accuracy and consistency of annotations. It can be achieved by:
Annotation tools – These facilitate the process of annotating text data. They can vary in terms of features, supported data types, and annotation techniques. Some popular annotation tools include:
Choosing the right annotation tool – It requires paying attention to:
Customizing annotation tools – It allows for customization to better suit your project needs like:
Annotation workflow – It ensures a smooth and efficient annotation process by:
Best practices – To create an effective annotation workflow:
Manage your annotation projects – You can achieve this by:
Evaluation Metrics – These are used to assess the performance of machine learning models trained on annotated data. Common evaluation metrics for text annotation include:
The role of human annotators in text annotation is crucial for the development of accurate and reliable AI and ML models. Human annotators manually label, tag, and classify data using data annotation tools to make it machine-readable, which is then used as training data for AI/ML models. They can perform various tasks, such as object detection, semantic segmentation, or recognizing text in an image.
Human annotators are trained professionals who can spot tiny details with high accuracy rates, ensuring that the annotated data is reliable for AI/ML project development.
Preference – Human-annotated data is preferred in many AI and ML applications due to its ability to provide a nuanced understanding of data, enabling models to navigate the complexities of human language and behavior more effectively.
Human annotators can adapt to new annotation tasks easily and often provide more accurate annotations than automated methods, especially for complex or ambiguous data. Furthermore, human annotators can identify and correct errors in existing labeled data, improving the overall quality of the dataset.
Accuracy – The accuracy of human-annotated data is critical for the success of AI and ML projects. Annotated data is essential for accurate understanding and detection of data input by AI and ML models. Human annotators are trained to spot minute details in large images or videos with high accuracy rates, ensuring that the annotated data is reliable for AI/ML project development.
The quality of annotated data directly impacts algorithmic performance, and human annotators can leverage their contextual understanding and domain expertise to resolve any ambiguity, enhancing the quality and accuracy of annotations.
Unbiased nature of human-annotated data – While human annotators can introduce biases in the data annotation process, they also play a crucial role in mitigating biases in AI and ML models. Human annotators with expertise in understanding cultural and social norms can handle subjective judgments effectively, evaluating content based on context, intent, and potential harm.
By engaging in fact-based conversations around potential human biases and using debiasing tools, human annotators improve the model outcomes and provide more accurate and unbiased results.
In conclusion, human annotators play a significant role in the development of AI and ML models by providing accurate, nuanced, and unbiased annotated data. Their expertise and adaptability make them indispensable in creating high-quality training datasets, which leads to the development of superior machine learning models.
Advantages of human-annotated data:
Human annotators improve the accuracy and generalization of AI/ML models by providing well-annotated data that enables models to understand patterns and relationships. The quality of data annotation directly affects the accuracy and reliability of ML algorithms, and good quality data annotation can deliver significant cost benefits and advantages for an ML project.
Human-in-the-Loop (HITL) is a powerful approach that combines human expertise with AI-driven data annotation, ensuring accuracy and quality in the annotation process. This collaborative method addresses AI limitations, streamlines training data refinement, and accelerates model development, ultimately boosting performance and enabling more reliable, real-world applications.
For instance, Netflix uses HITL to generate movie and TV show recommendations based on the user’s previous search history. Google’s search engine also works on ‘Human-in-the-Loop’ principles to pick content based on the words used in the search query.
HITL has several advantages for ML-based model training, especially when training data is scarce or in edge-case scenarios. As more people use the software, its efficiency and accuracy can be improved based on the HITL feedback. This approach not only makes machine learning more accurate but also helps humans become more effective and efficient in their tasks.
Natural Language Processing (NLP) technologies have a wide range of use cases, including neural machine translation, Q&A platforms, smart chatbots, and sentiment analysis. These technologies have experienced significant growth in recent years, driven by the increasing demand for advanced solutions across various industries and applications.
These statistics demonstrate the growing importance and adoption of NLP technologies across various industries and applications. The increasing use of artificial intelligence and machine learning technologies is expected to fuel further market growth and innovation in the coming years.
The future of text annotation is poised for significant growth and innovation, driven by the increasing demand for high-quality annotated data in AI and ML applications. As the global data annotation tools market is projected to reach USD 13,287.9 million by 2030, the need for efficient and accurate text annotation techniques will continue to rise.
Emerging technologies, such as deep learning and transfer learning, are expected to further improve the accuracy and efficiency of text annotation processes. Additionally, the integration of human expertise with advanced AI models will lead to more effective semi-automatic annotation techniques, striking a balance between manual and automatic annotation.
Industry trends, such as the growing adoption of AI in various sectors, will drive the demand for high-quality text annotation services. Challenges, such as scalability, cost, and language diversity, will need to be addressed to ensure the success of AI and ML projects.
Nothing wrong if we say that the future of text annotation is bright, with advancements in technology and industry trends propelling the field forward. As AI and ML continue to evolve, the importance of high-quality text annotation will only increase, making it a critical component in the development of accurate and reliable AI models.
Text annotation plays a crucial role in the development of accurate and reliable AI and ML models. High-quality annotated data is essential for training AI models, as it provides the necessary context and structure for the models to identify patterns and classify data. The importance of well-annotated data for achieving high accuracy in AI models cannot be overstated, as it directly impacts the performance, accuracy, and reliability of AI models.
The demand for high-quality text annotation and its importance in various industries and applications is growing continuously. By leveraging the expertise of human annotators and adopting best practices in text annotation, businesses can ensure the success of their AI and ML projects and achieve high accuracy in their AI models.

What’s next? Message us a brief description of your project.
Our experts will review and get back to you within one business day with free consultation for successful implementation.
Disclaimer:
HitechDigital Solutions LLP and Hitech BPO will never ask for money or commission to offer jobs or projects. In the event you are contacted by any person with job offer in our companies, please reach out to us at info@hitechbpo.com


