Data extraction transforms raw, scattered information into structured, usable datasets. Using AI, automation, and scalable techniques, companies can ensure accuracy, compliance, and efficiency that powers analytics, automation, and decision-making.
Data is gold, we all know that. However, the question is how to sift the gold from the dirty ore. That is why we need data extraction. First, you need to identify your data extraction source. Next you figure out the data extraction technique that works best for you. Leveraging AI and automation helps you with data extraction, and you must stay updated on latest trends to maintain efficiency and accuracy. Or you could use a professional data extraction service to extract data.
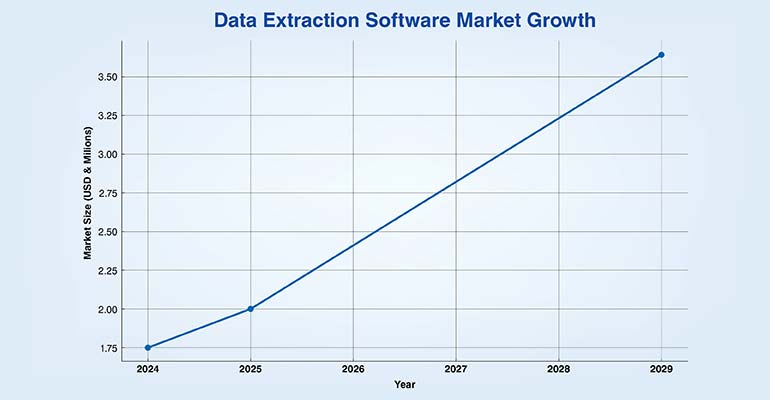
With data projected to hit 175 zettabytes globally data extraction can’t be ignored. To keep up with the data extraction demands the global data extraction market is growing rapidly at an estimated market size of $3.4 billion from 2025 to 2029. A 15.9% compound annual growth rate is phenomenal growth.
With 80% of data being unstructured and untapped, investing in automated data extraction techniques is really important.
Let’s explore what is data extraction, methods of data extraction and examples of real life data extraction.

Data extraction refers to the act of pulling raw data from different sources such as databases, websites, invoices, Excel spreadsheets, PDFs etc. The data pulled can be in different forms structured, unstructured or sometimes a combination of both. The extracted data is then standardized in a format as required. After this the data is centralized for storage which can be either onsite or in the cloud.
It’s important not to confuse data extraction with data collection. These two are very different processes. While data collection gathers data directly from its source (primary or secondary), data extraction utilizes data from a pre-existing source. Data extraction is the first part of ETL (Extract, Transform, Load) pipelines, extracting feeds from various data sources, transforming that data and then loading it to a relational database. It is the first layer that feeds processed raw data to all system and processes.
Many teams are currently using ELT (Extract, Load, Transform), instead of ETL which can be slow because ETL transforms the data on a separate server prior to loading. ELT loads the data and then transforms it, making it much quicker overall.
Without data, your decisions are based on hunches. Data can reveal patterns, identify insights, indicate risks and allow for quicker actions than others. It can even allow you to act before others have even seen the shift.
And how do you obtain that data? Through extraction. This is why it is so important – it unlocks a universe of insights.
Here’s the value it brings:
- Cross-system visibility: Data can be extracted from emails, CRMs, ERPs and websites so teams don’t work in silos.
- Smarter decisions: Organizational data from sites, or databases or invoices can be converted into action.
- Lower cost: Save time, reduce errors and focus your energy on high value work.
- Competitive advantage: Monitor trends by extracting insights from reports, competitor websites or from customer feedback.
- Big data: Work with millions of data points concurrently together – efficiently.
- Audit ready: Your data will always be organized, and its audit will never pose an issue.
Ready to automate data extraction for accuracy?
Data extraction is dependent on the source and purpose for which you are extracting. Sometimes manual extraction will be sufficient. Other times you’ll need automation or smarter tools.
Web data extraction
Web scraping is the method of extracting data from web data sources. It can mean a retailer monitoring the prices of products. Or a business following the competitor’s updates.
Basic scrapers use Python scripts or application programming interfaces (API). Dynamic websites may add additional layers of complexity since the content is generated using JavaScript as opposed to plain HTML. In those situations, you will need to use headless browsers. CAPTCHAs may also be an obstacle, requiring human intervention.
It’s important to follow robots.txt directives, site rules, and comply with the privacy laws. Ultimately, when done correctly, scrapping can provide more credible and reliable data than depending on 3rd persons or vendors.
Extraction from structured sources
Data extraction from structured sources involves systematically capturing and transforming information stored in databases, spreadsheets, CRMs, and ERP systems into usable formats for analysis and integration. Using APIs, SQL queries, and automation scripts, data is retrieved with precision and consistency.
This data extraction technique ensures schema compliance, metadata integrity, and referential accuracy across relational tables. It enables organizations to consolidate financial records, product catalogs, customer profiles, or clinical data without disrupting existing data architectures.
Advanced parsing logic and ETL pipelines streamline extraction from multiple structured environments, reducing manual intervention. The outcome is clean, validated, and query-ready data that supports downstream analytics, reporting, and AI model training.
Extraction via APIs
Extraction via APIs enables direct, secure, and structured access to data from multiple digital platforms and enterprise systems. APIs provide standardized endpoints that facilitate controlled data retrieval without compromising system performance or security.
Through RESTful and GraphQL interfaces, data can be extracted in real time or batch mode based on business logic and authentication protocols. API-driven extraction supports pagination, rate limiting, and version management to maintain data consistency across updates. It ensures interoperability with CRMs, ERPs, financial systems, and eCommerce platforms.
Document & Text Extraction (OCR, PDFs, Images)
Document and text extraction from OCR, PDFs, and images converts unstructured content into machine-readable data for processing and analysis. Optical Character Recognition identifies characters, tables, and key-value pairs from scanned or image-based files, maintaining layout accuracy and data hierarchy. The process includes pre-processing steps such as de-skewing, noise reduction, and text normalization to improve recognition accuracy.
Extracted data is validated through rule-based parsing and metadata tagging to ensure compliance and consistency. This method supports high-volume document workflows across invoices, contracts, medical records, and property documents.
Hybrid / Intelligent Extraction Methods
Hybrid or intelligent extraction methods combine rule-based automation with machine learning and natural language processing to handle both structured and unstructured data. This approach adapts to varying document formats, data sources, and semantic contexts, ensuring higher accuracy and scalability.
AI models detect entities, classify content, and interpret context, while deterministic rules manage validation and exception handling. The integration of OCR, NLP, and API-based extraction creates a unified workflow that optimizes data capture from diverse inputs such as forms, PDFs, and transaction logs. Continuous learning mechanisms refine extraction models over time, reducing manual correction.
How to choose the right data extraction techniques
Selecting the right data extraction approach depends on the nature, scale, and operational context of the data source. Key factors include:
- Type and structure of source data: Structured, semi-structured, or unstructured formats dictate the extraction method. Relational databases require SQL-based extraction, while websites or PDFs need scraping or OCR. Understanding schema consistency, data models, and content variability ensures the right balance between automation and precision.
- Volume and frequency: Large, continuous data streams demand scalable, real-time APIs or ETL pipelines. Smaller, periodic datasets suit batch extraction. Frequency affects infrastructure choice, resource allocation, and monitoring requirements, directly influencing performance, cost efficiency, and system responsiveness in production workflows.
- Stability of source: Dynamic websites, API updates, or layout changes affect extraction reliability. Techniques must accommodate schema drift, endpoint modifications, and markup volatility. Incorporating adaptive scripts, version tracking, and monitoring tools minimizes data loss and reduces maintenance overhead in unstable or frequently updated environments.
- Legal and compliance constraints: Extraction must respect data ownership, robots.txt rules, and platform terms of service. Adherence to GDPR, HIPAA, or PCI-DSS is mandatory for sensitive data. Implementing controlled access, anonymization, and audit trails mitigates legal exposure and ensures compliance with industry-specific regulatory frameworks.
- Cost, maintenance, and error handling: Each technique involves trade-offs between setup complexity, operational costs, and upkeep. Automated systems need robust exception handling, logging, and recovery mechanisms. Selecting tools with maintainable codebases and clear error diagnostics helps reduce downtime, improve throughput, and sustain extraction efficiency over time.
- Latency and freshness needs: When time-sensitive decisions rely on current data, real-time extraction via APIs or event-driven architectures is preferred. For historical or trend analysis, periodic batch processing may suffice. Balancing latency tolerance with system load ensures optimal performance and data relevancy across use cases.

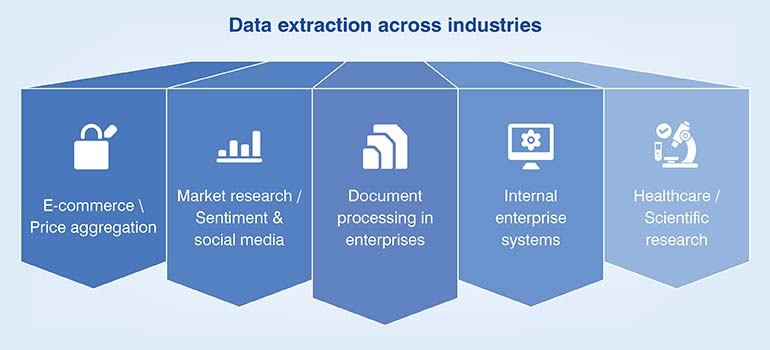
In real-world projects, data extraction is used across numerous industries and business functions to collect, organize, and analyze data from a variety of sources. It is often the first step in a larger data analytics, business intelligence, or machine learning project. Here are examples of data extraction from real projects, categorized by industry and application:
- E-commerce / Price aggregation: Extraction pipelines collect competitor prices, product metadata, and catalog updates from multiple online marketplaces. Data is normalized and mapped to internal taxonomies for pricing analytics, dynamic repricing, and product benchmarking. Automated schedulers maintain data freshness while minimizing API call costs and scraping frequency overheads.
- Market research / Sentiment & social media: APIs and crawlers capture user-generated content – posts, comments, and reviews – from social platforms and forums. NLP models process extracted text for sentiment scoring, entity recognition, and trend detection. These insights feed dashboards that guide marketing strategy, customer perception analysis, and brand reputation monitoring in near real time.
- Document processing in enterprises: OCR-driven extraction captures structured data from invoices, receipts, and KYC documents. Intelligent parsing identifies line items, totals, and identifiers while validating data against business rules. The extracted content is indexed, categorized, and integrated into enterprise accounting or compliance systems for automated reconciliation and audit readiness.
- Internal enterprise systems: Data extraction from CRMs, ERPs, and legacy systems uses secure connectors, SQL queries, or middleware integrations. It supports data consolidation, migration, and analytics initiatives. Automated workflows ensure schema consistency, referential integrity, and controlled access, enabling unified enterprise data visibility across departments and operational processes.
- Healthcare / Scientific research: Extraction workflows parse structured and unstructured content from research journals, clinical forms, and EHRs. NLP and ontology mapping identify key medical entities, parameters, and study results. The extracted datasets support evidence-based insights, regulatory submissions, and AI model training for diagnostics and medical research applications.
Data extraction is critical for modern business intelligence, but the process presents significant technical hurdles. Overcoming these common challenges requires robust, well-engineered strategies.
| Challenge Area |
Problem |
Best Practice |
| Diverse Data Formats |
- Unstructured data sources
- Inconsistent schema layouts
- Complex parsing logic
- Fragmented data models
|
- Use ETL connectors
- Normalize data formats
- Automate schema mapping
- Build unified datasets
|
| Data Quality Issues |
- Inaccurate data fields
- Missing or null values
- Duplicate records
- Corrupted analytics outputs
|
- Automate data validation
- Apply cleansing scripts
- Enforce business rules
- Monitor data pipelines
|
| Dynamic Data Sources |
- Frequent layout changes
- Broken extraction scripts
- Pipeline disruptions
- rework required
|
- Design resilient scrapers
- Use adaptive selectors
- Implement change detection
- Automate script updates
|
| Scalability and Performance |
- Processing bottlenecks
- Slow response times
- High data latency
- Limited infrastructure capacity
|
- Use distributed frameworks
- Enable parallel processing
- Optimize data pipelines
- Scale on cloud clusters
|
| Legal and Compliance |
- Regulatory restrictions
- GDPR non-compliance risks
- Platform access limits
- IP blocking issues
|
- Integrate compliance checks
- Rotate proxy servers
- Review policies regularly
- Mask sensitive data
|
| Complex Nested Structures |
- Deeply nested JSON/XML
- Hard-to-access fields
- Parsing inefficiencies
- Data tree complexity
|
- Use advanced parsers
- Flatten data hierarchies
- Apply recursive logic
- Automate data traversal
|
Data extraction is evolving rapidly, driven by AI, real-time systems, and regulatory demands. Emerging technologies enable smarter, faster, and more compliant data acquisition across industries.
- Rise of AI / ML-powered extractors: Machine learning models enable extraction systems to adapt automatically to new formats, layouts, and schemas. These AI-driven extractors reduce manual intervention while improving accuracy and scalability across diverse data sources.
- Semantic / context-aware extraction: NLP techniques and knowledge graphs allow systems to understand context and meaning within unstructured data. This enables precise entity recognition, relationship mapping, and richer, actionable insights for analytics.
- Real-time / streaming extraction architectures: Modern pipelines support continuous data ingestion from APIs, logs, and event streams. Real-time architectures reduce latency, enabling up-to-date dashboards, dynamic decision-making, and responsive enterprise operations.
- Greater regulation, privacy, and data governance impact: Compliance with GDPR, HIPAA, and other frameworks shapes extraction strategies. Built-in privacy, audit trails, and access controls ensure lawful, secure, and ethical handling of sensitive data.
- Integration with large-scale analytics & AI systems: Extracted data increasingly feeds AI models, predictive analytics, and enterprise intelligence platforms. Seamless integration ensures clean, structured, and enriched datasets drive actionable business outcomes efficiently.
Conclusion
Data extraction is a critical process for transforming raw information from diverse sources into structured, actionable datasets. From structured databases to unstructured documents, organizations leverage techniques like API extraction, OCR, and hybrid methods to enable analytics, automation, and AI initiatives. Successful implementation requires careful planning, robust validation, and compliance adherence. As data volumes grow, intelligent, scalable, and context-aware extraction pipelines will be essential for maintaining accuracy, efficiency, and competitive advantage across industries.
Transform raw, scattered information into structured, usable datasets.
Contact us now »