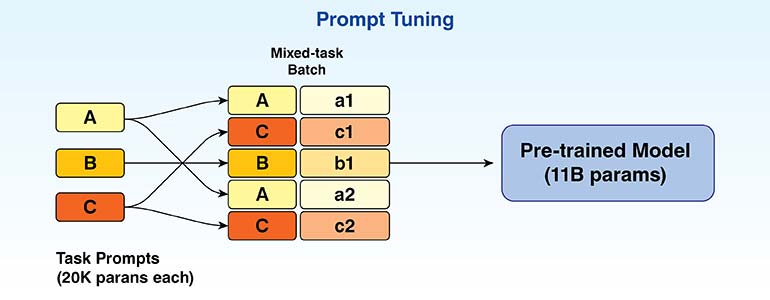
LLMs are good at handling general tasks, but specialized tasks typically need expensive model retraining. Prompt tuning addresses this by training small embeddings while keeping models frozen. Prompt fine tuning provide specialized performance effectively, without months of computation or high costs.
Large language models handle common applications like search and support just fine out of the box. But when you need one for a specific task or rigid workflow, that’s where things get tricky. Full fine tuning adjusts billions of parameters and will absolutely destroy your cloud budget. Plus, you’ll create a versioning nightmare that slows down your entire team. The problem is straightforward: we need a lightweight method to teach the model from our data without this massive overhead.
Prompt tuning gives you that lightweight path. Keep the base model frozen and only train a small set of learned prompts to get the behavior you want. You don’t need to copy the entire model or make risky weight changes. Training happens faster, the resulting artifacts are tiny, and you can easily roll back if an update fails. For most day-to-day tasks, it’s perfect because it adapts the model without forcing you to rebuild your entire stack.
What is prompt tuning for LLMs and why it matters
There are many ways to adapt large models, and each comes with trade-offs between control and efficiency. We find prompt tuning sits in an ideal middle ground. It’s fast, cost effective and leaves the base model untouched. That’s an important advantage for maintaining a stable production environment. You’re teaching a machine that already understands language and how to do a specialized job. There are two kinds of prompts.
Soft vs hard prompts trade-offs
| Attribute |
Soft prompts |
Hard prompts |
| Interpretability |
Low |
High |
| Robustness |
High |
Variable |
| Storage footprint |
Tiny |
None |
| Readability |
None |
Textual |
There’s a simple rule of thumb: start with hard prompts (plain text) to validate your concept. Use hard prompts for initial clarity and prototyping. Use soft prompts for scalable production deployment. That should be your guiding principle.
Why prompt tuning for LLMs matter
Now let me clear the myth around why it matters the most. You’re training a small vector called a soft prompt. This component directs the base model’s behavior for your task, while the model itself remains unchanged. The only new element is the prompt. That makes this an elegant and efficient solution. The power of this simple concept lies in its practical application and scalability.
Why LLM prompt tuning comes handy
- It scales very efficiently: You can support a ton of tasks with new prompts all while using just 1 base model.
- Swapping is easy: Deploying a new task is just a matter of loading a new prompt. You don’t have to touch the core model and risk breaking anything in production.
- It’s inexpensive: The cost is a tiny fraction of what full fine tuning requires, which makes getting budget approval way easier.
Parameter footprint and prompt tuning
You have several options for prompt placement. The best choice depends on the specific problem you’re trying to solve.
- Input prompts: This is our standard starting point for most tasks because it’s simple and fast.
- Prefix prompts: We use these when we’re generating longer, structured text, say for example styled writing. They give you a lot more control over the final output.
- Deep prompts: You’ll want to use these when you need precise word by word accuracy but they can be more complex to set up.
- Hybrid methods: We combine prompt tuning with other techniques when 1 method isn’t enough and we can’t touch the base model.
How to pick the best LLM prompt tuning method
- Start with plain text prompts. You can validate your entire task design this way and often achieve 80% of your goal with this one simple step.
- Move to soft prompt tuning. This is the right step when you need scalable production ready performance.
- Try adapters like LoRA if you need more model capacity but lack the budget for a full retrain.
- We reserve full fine tuning as a last resort.
- Use it only when absolute maximum accuracy is non-negotiable and cost isn’t a factor.
Why prompt tuning is important for LLMs to adapt new tasks
When enterprises rely on a strong base model but face a flood of new tasks, full fine-tuning quickly becomes impractical. Training billions of parameters inflates costs, creates operational overhead, and may not even be allowed by vendors. Prompt tuning solves this by freezing the base model and training small, lightweight adapters. These “soft prompts” enable efficient adaptation, preserve general capabilities, and drastically reduce per-task costs.
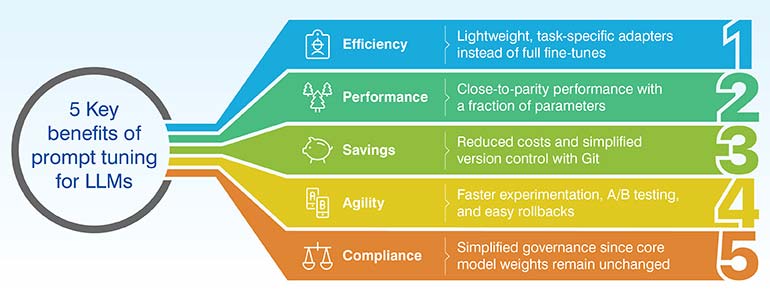
Prompt tuning offers enterprises a practical, cost-effective path to scale AI across diverse workloads. By reducing training overhead, ensuring compliance, and keeping operations lean, it empowers teams to adapt quickly without compromising performance. For many organizations, it’s the smarter alternative to costly retraining—and the future of sustainable AI deployment.
Want to tune your prompts and make your LLMs smarter?
Why prompt tuning for LLMs is more popular than fine-tuning
Prompt tuning is becoming increasingly popular compared to fine-tuning because it provides a quicker, more affordable, and more efficient method to fine-tune large language models to new tasks. Fine-tuning traditionally involves retraining billions of parameters with enormous compute, time, and budgets, usually unfeasible for most teams.
Prompt tuning, however, updates merely small task-specific embeddings while holding the base model constant. This light-weighting style allows it to roll out several domain-specific applications without training from scratch. The outcome is efficiency, reusability, and accessibility, making it possible for organizations to tap into specialized performance with few resources, resulting in its immediate uptake across sectors.

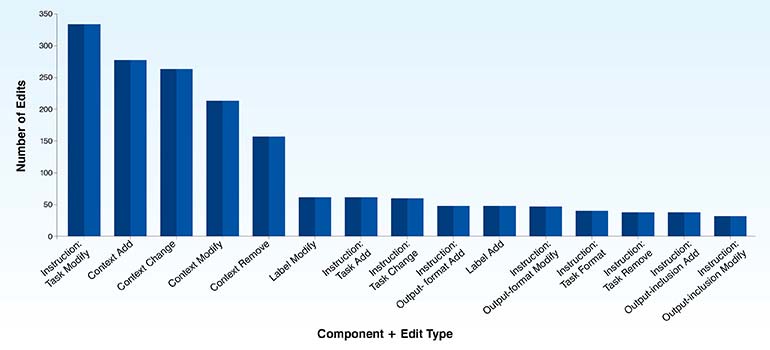
The most common types of edits applied are tuning the prompt in which the general meaning of the prompt remains consistent, followed by additions, changes where the meaning does not stay the same, removals and formatting.
The findings here underpin the criticality of tuning prompts to make them user-friendly and help prompt engineers to navigate the complexity of prompt design. This is also crucial as language models are becoming increasingly integrated into enterprise workflows.
Libraries like Hugging Face’s PEFT make the whole process straightforward, letting you graduate from simple prompt engineering to tuned prompts. Other methods like LoRA might be better for long form generation, but prompt tuning excels in fast setup and minimal storage requirements. It converts LLM adaptation from a massive, one-off research project into a repeatable, scalable process.
LLM prompt tuning variants understanding task signal entry points
This is more than just basic tweaking. We’re strategically injecting the prompt signal right where it will be most effective. Think of it like adjusting a mixer: you choose where the signal goes and how strong it is. This decision depends entirely on your task, data availability and delivery timeline.
| Method |
What it does |
Why it helps |
Best suited for |
Cautions / Notes |
| Input Prompt Tuning |
- Prepends learned vectors
- Added to input
- Simple mechanism
- Lightweight design
|
- Straightforward method
- Rapid training
- Easy deployment
- Efficient use
|
- Basic classification
- Short Q&A
- Defined rules tasks
- Simple workflows
|
- Negligible memory impact
- Start experiments here
- Best first choice
- Minimal overhead
|
| Prefix Tuning |
- Inserts virtual tokens
- Into key states
- Into value states
- Alters attention
|
- Persistent guidance
- During generation
- Not just start
- More control
|
- Long-form writing
- Summarization tasks
- Tone-sensitive tasks
- Structure-critical tasks
|
- Larger memory footprint
- May add latency
- Trade-off control
- Higher cost
|
| Deep Prompt Tuning (P-Tuning v2) |
- Distributes signals
- Across multiple layers
- Injects task vectors
- Deeper integration
|
- Word-level control
- Sequence labeling
- Structured outputs
- Strong precision
|
- NER tasks
- Token classification
- Data extraction
- Unstructured text
|
- More hyperparameters
- Start lean config
- Tune carefully
- Avoid complexity
|
| Hybrid Methods |
- Combines soft prompts
- With LoRA adapters
- Extra parameters
- Base frozen
|
- More flexibility
- Beyond prompt tuning
- Not full fine-tune
- Balanced approach
|
- Complex NLU
- Multilingual tasks
- Accuracy-focused jobs
- Advanced needs
|
- Larger artifacts
- Still smaller than fine-tune
- Manage sizes
|
Some quick tips
- Go with input prompts when you need speed and simplicity.
- Prefix tuning is what we use for controlling longer outputs and nailing specific styles.
- You’ll need deep prompts when precise, token level labeling is a must.
- And hybrids? They’re our escape hatch when soft prompts alone just don’t have enough muscle.
How prompt tuning for LLM works

Prompt tuning begins with a frozen base LLM, where only small trainable prompts are optimized. You define prompt length and placement, then train using task-specific data. Unlike full fine tuning, only the prompt’s parameters update, keeping the model fixed. Training stability relies on validation monitoring, careful hyperparameters, and balanced dataset.
Once trained, the prompt file attaches at inference, guiding task-specific behavior efficiently without retraining the entire model.
Key considerations include:
- Prompt length: Trade-off between speed and capacity
- Initialization: Random or derived from word embeddings
- Placement: Input for structured tasks, prefix/deep for longer generation
- Training stability: Low learning rate, warmup, early stopping, gradient clipping
Prompt tuning balances efficiency and control, enabling targeted LLM adaptation with minimal overhead—streamlining deployment while retaining stability, scalability, and strong performance across diverse tasks.
What good adaptations of prompt tuning for LLMs look like
Successfully adopted prompt tuning balances efficiency, accuracy, and scalability. It uses lightweight embeddings to specialize large models without retraining, achieves consistent task performance across domains, minimizes compute costs, and ensures reusability. It leads to faster deployment, precise outputs, and adaptability to evolving business or research needs.
- Report trusted metrics. Beyond accuracy or macro-F1 you should include a calibration metric like Expected Calibration Error (ECE) to make sure the model’s confidence scores are actually reliable.
- Test for robustness. Evaluate performance on a domain shifted dataset to see how the model will behave on slightly different data. Also show how performance holds up with limited labeled examples.
- Adjust your strategy based on data volume. With only a few hundred labels, prefix or deep prompts often do better.
- With thousands of labels, basic input prompt tuning can get you surprisingly close to full fine tuning performance at a fraction of the cost.
- Recognize the impact of model size. A larger base model gives the prompt more capacity to use which often leads to higher accuracy. This is a direct trade-off you have to manage between performance, latency and cost.
How to tune prompts to help LLMs adapt new tasks
When you have one model but a dozen different tasks, prompt tuning is your most effective approach. We use a small, dedicated prompt for each task and leave the main model untouched. This helps us rapidly roll out updates and new capabilities. We only use heavier tools like adapters when we absolutely must. Now let’s check out on how to choose the right prompt tuning tool.
How to choose the right tool
Prompt tuning is our default choice for most common tasks because it’s lightweight and flexible. For more complex jobs like named entity recognition or parsing unstructured documents, prefix or deep prompts are probably what you need.
Add LoRA or a hybrid setup when you need more power but a full retrain is off the table due to budget constraints. Nothing beats full fine tuning for mission critical tasks where every point of accuracy matters, but these scenarios are rare in practice. When dealing with rapidly changing information, you should combine prompts with retrieval augmented generation (RAG) to make sure you have factual accuracy.
For initial exploration, always start with text prompts. Once you find a pattern that works well, formalize it as a trainable soft prompt.
Comparison prompt engineering vs fine-tuning vs prompt tuning
We adhere to a default strategy. Prompt tuning for scalable tasks, prefix or deep prompts for difficult NLU jobs, LoRA when more capacity is needed and full fine tuning only when a budget owner mandates it. This pragmatic approach has proven effective.
| Method |
Trained params per task |
Serve-time footprint |
Strengths |
Gaps |
| Prompt tuning |
~0.01–3% |
Base + small prompt |
- Rapid multi-task swap
- Efficient training
|
Lower interpretability than text |
| Prefix / deep prompts |
0.1–3% |
Base + per-layer states |
- Stronger NLU
- Handles long outputs
|
More tuning knobs |
| LoRA |
~0.1–1% |
Base + low-rank adapters |
Higher capacity within PEFT |
Heavier than pure prompts |
| Full fine-tuning |
100% |
One model per task |
Maximum task control |
High cost and storage |
| Few-shot in context |
0% |
Base only |
Instant trials in the prompt window |
- Brittle across tasks
- Window limits
|
| Prompt engineering |
0% |
Base only |
- Quick iteration
- UX exploration
|
Stability varies by task |
Top cross-industry applications for prompt tuning
Prompt tuning works particularly well for chatbots with well-defined tasks, like document summarization or PII redaction. It’s also an excellent tool for rapid prototyping when you need to demonstrate a concept quickly.
| Use Case |
Your Data |
Prompt Pattern |
What You Get |
How to Deploy |
| Enterprise NLP Pipelines |
- Emails
- Tickets
- Internal policies
- System logs
- Unstructured data
|
- Schema-first extraction
- Few-shot examples
- Strict JSON output
- Mask PII
|
- Structured entities
- Intents
- Priorities
- Direct system input
- No manual cleaning
|
- Unit-specific adapter
- Batch or streaming
- Log inputs/outputs
- Enable auditing
|
| Chatbot Adaptation |
- FAQs database
- Product docs
- Release notes
- Chat logs
|
- RAG with style
- Clear refusal rules
- Policy enforcement
- Tone guidance
|
- Context-aware answers
- With citations
- Next steps
- Suggested actions
|
- Brand-based adapter
- Region-specific tuning
- Cache queries
- Offline evaluation
|
| Custom Document Summarization |
- Legal contracts
- Research reports
- Case files
- Long documents
|
- Role-guided summary
- Fixed sections
- Strict token limit
- Concise format
|
- Concise briefs
- Key entities
- Risk flags
- Deadlines summary
|
- Batch processing
- Human-in-loop
- Risk review
- Store results
|
| Academic Research |
- Research papers
- Citation graphs
- Public datasets
- Code repositories
|
- Two-pass method
- Extract key facts
- Compare claims
- Cite sources
|
- Neutral summaries
- Abstract, methods, results coverage
- Limitations noted
|
- VPC deployment
- Topic-specific adapter
- Standard export
- Markdown format
|
How to build and deploy prompt tuning workflow for LLMs
Building a prompt tuning workflow requires a structured approach from defining objectives and preparing balanced data to designing, training, testing, and deploying prompts with continuous monitoring for evolving business needs.
- Define the Task and the MetricFirst be very clear about your objective. Select a primary success metric (like macro-F1) and a secondary diagnostic metric (like ECE for calibration).
- Prepare Your DataWe need to make sure our input output pairs are clean and balanced. We also apply safety filters and include a diverse set of edge cases to improve robustness.
- Design the Prompt Start by iterating on a clear text prompt with stable label words. Once that pattern is validated, we convert this “hard prompt” into a trainable “soft prompt.”
- Train the Prompt Use a standard library like PEFT or OpenPrompt. Start with input prompt placement before trying more complex methods like prefix or deep tuning. Also use learning rate warmups and early stopping to prevent overtraining and wasted compute.
- Evaluate Your Results Beyond quantitative accuracy, test for qualitative robustness using varied inputs like typos or out of domain queries. For generative tasks you should manually review outputs for style, tone and factual correctness.
- A/B Test and Iterate Systematically test different prompt lengths, placements and initializations. Document your experiments and promote the version that best meets your quality and performance targets.
- Deploy and Monitor Organize prompts in a registry, load them dynamically and continuously monitor production performance. Be always ready to retrain and update prompts as your data and business evolve.
Adapt faster, deploy smarter, and achieve more with less compute.
Checklist for building an LLM prompt tuning workflow:
- A clear task definition and goal.
- Your primary metric for success.
- Clean, balanced data with safety filters applied.
- A solid seed prompt with defined label words.
- Training done with a standard library like PEFT or OpenPrompt.
- Evaluation based on macro-F1 or ROUGE and we always include ECE.
- Documented A/B tests that have a clear rollback plan.
- Prompt registry and a basic monitoring dashboard.
Deploying the workflow for multi-task life
- Prompt Registry: A central repository is crucial for managing prompts at scale. With it, you can match each task to its corresponding prompt file. You load the base model just once and then the setup dynamically attaches prompts to each incoming request.
- Versioning, A/B Testing, and Rollback: We run different prompt versions side by side to figure out which one performs better. Because the artifacts are small, you can promote a new version instantly or roll back a failed deployment just as quickly. This makes sure we have operational stability.
- Multi-Tenant Models: This pattern works well for serving multiple clients or teams from a single model instance. Each tenant gets their own dedicated prompt, so their task specific behaviors stay isolated, and performance stays consistent
A well-designed prompt tuning workflow ensures efficiency, adaptability, and consistent performance helping your models stay reliable, cost-effective, and aligned with changing business goals.
Benefits and limitations of tuning prompts for LLMs
The main benefits of prompt tuning are fast training and trivial swapping of tasks. Operationally the key advantage is that the base model remains untouched, ensuring stability and protecting it from any experimental changes.
Things to Watch Out For
Soft prompts are non-interpretable vectors, so robust logging and evaluation are important to understand their behavior. They can also overfit to strange patterns in your data, so proper data splitting and careful training are necessary. And avoid trying to merge too many tasks into a single prompt.
Always clean your data, restrict prompt access for privacy and maintain a human in the loop for compliance in sensitive domains.
Tools and frameworks supporting prompt tuning for LLMs
| Framework |
Supported Methods |
Key Features |
| HuggingFace PEFT |
Prompt, Prefix, LoRA |
Common backbone integration |
| OpenPrompt |
Templates, Verbalizers |
Training loops, Plug-and-play tasks |
| Ops add-ons |
Registry, Dashboards |
Cost/quality tracking |
No matter which tool you choose, just make sure it gives you robust experiment tracking, a central prompt registry and a dashboard for monitoring performance and cost.
Conclusion
Prompt tuning is a practical and scalable method for adapting LLMs without crazy costs. We train small, focused prompts while keeping the base model frozen. You can iterate faster, reduce compute bills and deploy new capabilities in a reasonable amount of time.
This gives us a major operational advantage. A shared prompt library helps you reuse and update work across different projects, improving consistency. This approach also satisfies audit and compliance requirements without slowing down development. You get the specific task control you need without the massive overhead of traditional fine tuning.
So, here’s what you do.
- For experimentation: Start with text prompts to look at and validate ideas freely.
- For scaling: Use a prompt registry organized by task or team to manage your prompts effectively.
- For production: Train soft prompts, evaluate them rigorously and then deploy them into your serving environment.
You need to monitor performance continuously. Be prepared to update your prompts as your data and business needs change, because they will. Prompt tuning isn’t a silver bullet, but it’s a powerful, scalable tool that aligns with the practical realities of building and maintaining AI driven products.
Tune your prompts to see the difference in speed, scalability, and precision.
Let’s get started »