5 Tasks Real Estate Data Aggregators Should Automate and How
Snehal Joshi
May 19th, 202617 min read
Manual property data workflows cannot scale. Automating five core data aggregation tasks of collection, validation, enrichment, cleansing, and document processing cuts error rates. Crawlers, business rules, and AI models make this possible without proportional increases in staffing.
Real estate data now flows in from disparate sources including MLS feeds, county assessor portals, USPS delivery point databases, permit registries, FEMA flood zone maps and several other non-traditional sources such as neighborhood business activity APIs. Manual workflows are absolutely not capable of standardizing and maintaining voluminous property data across these sources at the update frequency that real estate portals, lenders, and PropTech platforms require. Manual data processing not only slows down the throughput, but it compounds error rates across every downstream system which purely depends on data.
The situation demands real estate data aggregators to automate five core tasks that include data collection, records validation, property data enrichment, data cleansing and document processing. Each of these tasks can be automated by using a combination of web crawlers, rules-based scripts, and AI/ML models. This article explains how each works and what throughput gains aggregators can expect.
HitechBPO has been successfully processing over 50 million property records for US based MLs providers, real estate data portals, and PropTech platforms every year. The benchmarking, implementation strategy and patterns prove their operational experience and robust workflows. The five tasks they propose real estate data aggregators to automate are the foundation of production-grade real estate data pipeline. Also, the three implementation methods showcased in Section 2 are the technical layers used to execute them.
Automate to process real estate data aggregation/collection at scale, pace, and quality.
5 Tasks Real Estate Data Aggregators Should Automate to Scale Property Data Operations
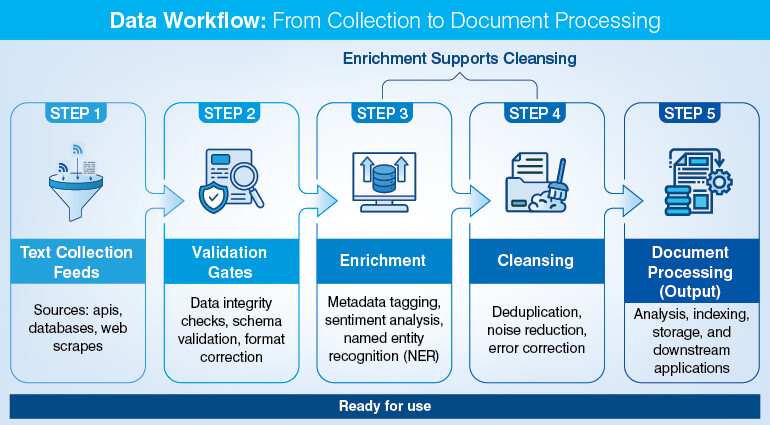
The five tasks that real estate data selling companies should automate are presented here in pipeline order; collection feeds validation, validation gates enrichment, enrichment supports cleansing, and clean records enable document processing.
Automating one task in isolation reduces friction at that point. Automating all five creates a self-sustaining data pipeline that scales without proportional increases in staffing.
Task 1: Automated property data collection from MLS feeds, public records, and non-traditional sources
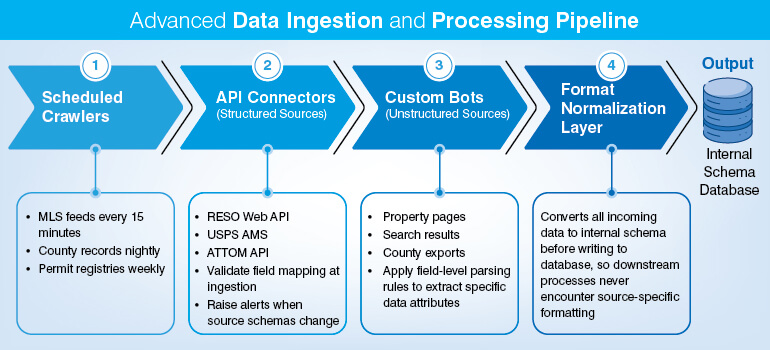
Leverage scheduled web crawlers, API connectors, and custom bots for continuously pulling data from MLS feeds, government property records, and non-traditional sources to automate property data collection. As a data aggregator you would have experienced that while collecting data manually you are forced to prioritize sources, which creates coverage gaps and makes your property data pipeline rely heavily on the speed of individual contributors.
Source diversity creates structural challenges in property data collection. It is so because:
MLS data comes through RESO Web API or legacy RETS feeds.
County assessor records are supposed to be exported as CSVs with non-standard field names.
Permit registries expose HTML tables.
USPS address validation runs through AMS (Address Management System) APIs.
So, it is evident that each source type requires a different extraction mechanism and a normalization layer to map incoming data in diverse fields to a consistent internal schema. Automated property data collection is equipped to handle it using this four components:
Scheduled Crawlers: These run at source-defined intervals like for MLS feeds every 15 minutes, every night for county records and every week for permit registries.
API connectors: These are helpful in validating field mapping at ingestion and raise alerts when source schemas change in structured sources like RESO Web API, ATTOM API, USPS AMS, etc.
Custom bots: These bots apply field-level parsing rules to extract specific data attributes from unstructured sources like HTML property pages, paginated search results, PDF county exports etc.
Format normalization: It converts all incoming data to the internal schema before adding it to the main database, ensuring downstream processes never face the challenge of source-specific formatting.
Property collection pipelines, designed specifically for MLS data, should comply with IDX feed agreements and RESO Data Dictionary field requirements. The collection process should also ensure that RESO-required fields that arrive empty or malformed are flagged at the time of data ingestion, and not when discovered later at the time of validation.
This robustness is very important for MLS providers who have SLA obligations to their subscribers. An MLS data aggregation services provider, for a New England real estate data firm, captured 28,000+ customer records from property documents across six US states using automated bots. The same pipeline handled volume spikes without process changes.
Task 2: Real estate data validation to catch 30% of records that decay every year
It is observed that in any given year, nearly 30% of property data in a typical real estate database becomes inaccurate due to change in contact details, reclassification of zones, reassessment of assessed values, transfer of ownerships, and many such reasons. There are more chances that a record accurate at the time of ingestion becomes incorrect by the time a downstream user wants to use it. That’s where automated data validation process walks into the picture. It checks records at the time of ingestion and revalidates them in a scheduled cycle.
Real estate data validation is all about confirming if a given records is correct and internally consistent. It also involves:
Verifying ownership against county assessor records
Confirming postal addresses against USPS Delivery Point Validation
Cross-referencing legal descriptions with GIS parcel data
Checking that field values fall within acceptable ranges
Some examples of validation failures due to manual review at scale:
Lot size of zero square feet
Sale date earlier than a listing date
Owner name that does not match the deed of record
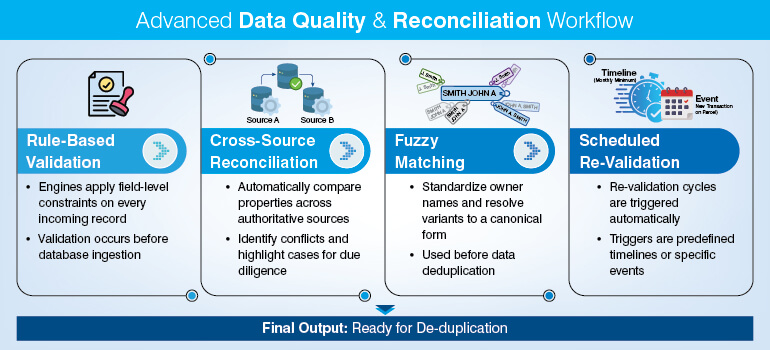
The automated validation stack typically includes:
Rule-based validation: Engines that apply field-level constraints on every incoming record before it is ingested in the existing database.
Cross-source reconciliation: Automatically compare the same property across two or more authoritative sources to identify conflicts and highlight such cases for due diligence.
Fuzzy matching: It is used to standardize owner names, resolve variants such as ‘John A. Smith’, ‘J. Smith’, and ‘SMITH JOHN A’ to a canonical form before deduplication.
Scheduled re-validation: Cycles triggered according to predefined timeline (monthly minimum) or by event (new transaction recorded against the parcel).
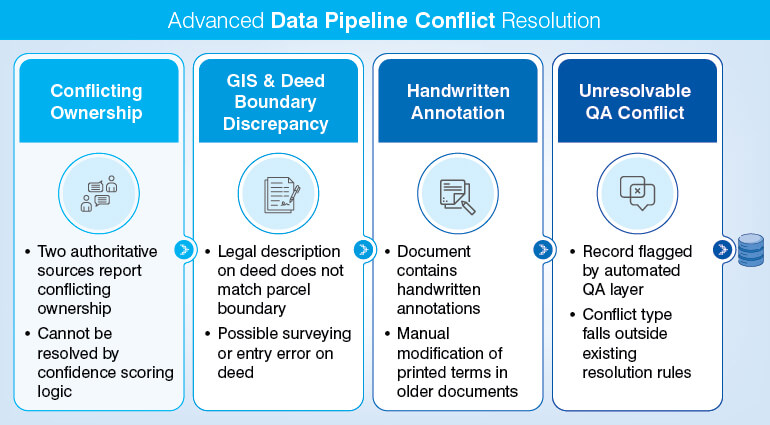
Property data validation pipelines should be designed to escalate errors and not auto-correct records where two authentic data sources conflict on a legally significant data field. Automated data validation systems should determine that a conflict exists, whereas it is the human data expert who determines data from which source to be considered.
Trust us, this is not a limitation of automation. Instead, it is a compliance design principle that real estate data selling companies evaluate when choosing a property data provider. Automated validation of 650,000+ records per month empowered one of the leading US real estate portal to provide property intelligence to subscribers. It improved their listing accuracy hence reduced data customer support escalations.
Task 3: Property Data Enrichment to append owner history, valuation signals, and geospatial attributes
Ownership status, lien status, permit activity, school district ratings, flood zone classifications and neighborhood metrics keep changing in base property records. Property data enrichment is what appends the latest and validated information from verified external data sources.
We need to understand that a basic MLS record contains only the information that a listing agent entered. So, we cannot expect it to contain assessed value history, prior sale chain, environmental hazard proximity, or geospatial attributes. And these are the data points that an automated valuation and underwriting model requires. This is the gap that real estate data enrichment closes.
The challenge here is that each of the attribute has a difference and diverse data source.
Data Type
Source Organization / System
Description
Tax Data
County Assessors
Property tax details and assessed property values
Flood Zone Classification
FEMA – National Flood Hazard Layer (NFHL)
Flood risk zones and hazard classifications
Ownership History
County Deed Registries
Historical property ownership and transfer records
School District Ratings
NCES / Commercial Education Data Providers
School performance metrics and district ratings
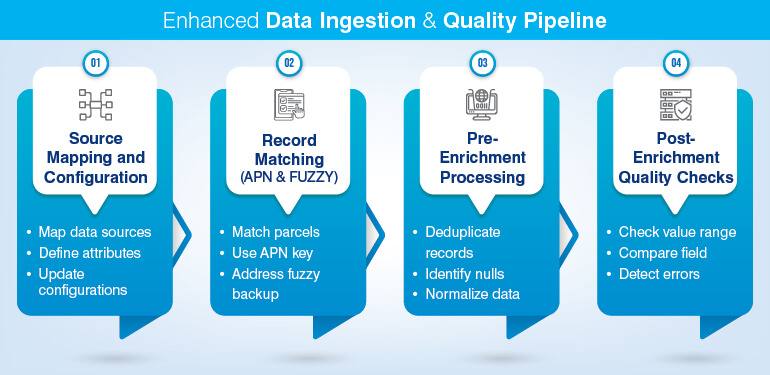
Your property data enrichment pipeline must know which source to tap for each of the attributes. Followed by matching the responses against each correct property record and then appending the data without overwriting existing fields.
Here’s a data architecture workflow. It details the entire pipeline from initial source mapping to the final quality checks, visualizing how clean records are maintained before being committed to the database.
To enhance property data, computer vision models analyze satellite and street-level photos to identify roof type, exterior materials, pools, and outbuildings. Text sources lack these details but are critical for insurance underwriters and lenders. This is what makes automated image analysis quintessential.
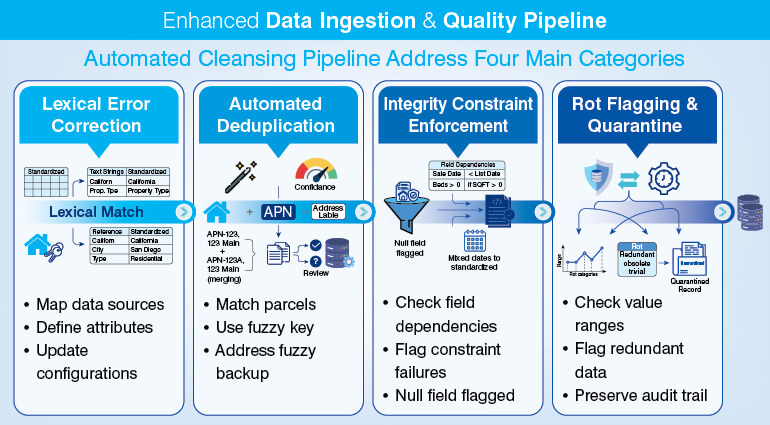
Task 4: Automate real estate data cleansing to eliminate duplicates, ROT data, and format inconsistencies
The data cleansing activity is meant to remove or correct property records that are either duplicate, outdated, incorrectly formatted, or internally inconsistent. Such data is referred to as ROT data – Redundant, Obsolete, Trivial data. In real estate databases, these instances crop up in predictable forms. You may find the same parcel listed under two different address, or a property already sold is marked as active, property records with date fields in mixed formats across county sources, and contradictory values where the same field holds different data in two records for the same property.
The need to cleanse property database scales with the increase or decrease in the size of the database. A real estate portfolio of about 1,00,000 property records will have so many duplicate and stale entries, that manual data reviews will fall short of. Taking up the manual data cleansing approach will produce a backlog, and not clean database.
Four main categories of your automated data cleansing pipeline:
Automated cleansing workflow should not decide which to keep and which not to, for records where two authentic sources conflict on a legally significant fields like ownership or legal description. The best way to deal with these records is to send them in the human review queue. Automated data cleansing should not resolve conflicting records unilaterally, instead it should identify those records and route them correctly.
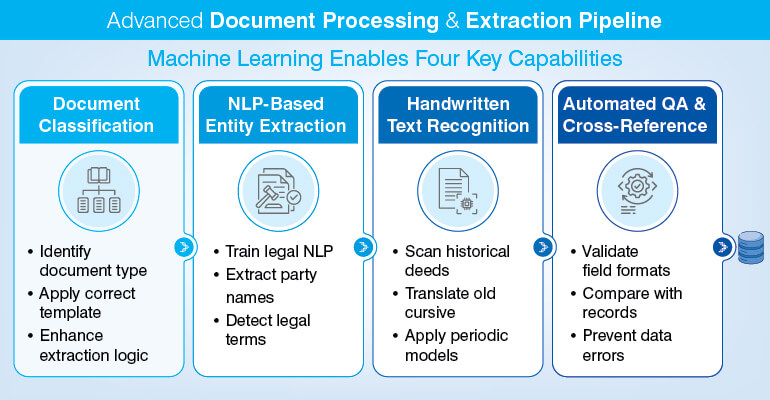
Task 5: Automate real estate document processing of title deeds, mortgage records, and OCR extraction
OCR (Optical Character Recognition) and NLP (Natural Language Processing) play a vital role in automating real estate document processing for extracting structured data from inspection reports, disclosure forms, title deeds, mortgage documents and several other real estate documents. And this is not it. The automation helps in converting text into database ready field. Automation at volume is the mantra for both the stages of this process, data extraction and data transfer.
Extracting data from a real estate document involves reading a document and identifying data fields like property legal description, recording data, owner name, lien position and loan amount, grantor and grantee company, and many more.
Data transfer means adding or writing the extracted values into the correct database fields while avoiding transcription errors.
Extracting property in form of handwritten annotations from dense legal documents, archaic legal terminology, or documents that are scanned poorly; is error prone and slow. When we talk about scalability, errors in data extraction contribute largely to errors in the main database. Here’s what a four layered automated document processing pipeline looks like:
Real estate listing sites using manual document processing workflows usually struggle to clear volumes which their existing teams cannot clear. Hiring real estate document processing services for automated data extraction, document processing and human supervised data entry workflow equipped with OCR and NLP extraction capabilities across deed, mortgage, and disclosure document types; not only helped them eliminate the coordination expenses between processing teams, but reduced per-document processing time.
How Should Real Estate Data Aggregators Automate Crawlers, Business Rules, and AI-Backed Pipelines?
So, we witnessed what all tasks should real estate data aggregators automate. Now is the time to define how to automate those tasks. In this section we will talk about three layers of implementing automated workflows. Mind well, these layers are not alternatives for one another, instead they complement each other and perform hand in hand. Most production real estate data pipelines use all three.
AI and ML backed pipelines handle unstructured data inputs and patterns with multiple complexities.
Layer 1: Business rules and automation scripts for data extraction and validation
Business rules are the logical foundation to any automation pipeline. These rules encode the decisions involved in what is a valid field value, which and when a record should be flagged, how to resolve conflicts between two authentic data sources, and what should the workflow do when a required data field is null. So basically, business rules eliminate the need of human intervention at every step of data processing. These business rules can be implemented in form of scripts that are triggered in three type of instances:
Validate incoming address fields against USPS postal standards,
Reject records where a RESO-required field is null, and,
Flag records where assessed value deviates >40% from comparable properties in the same ZIP code.
Each of the above rules represents a decision which was previously made by a human and now is consistently made at machine speed and without errors.
Maintaining these business rules according to changing source structures and business requirements is really important. Understand, if a data pipeline working on rules defined two years back, for a source that has revised its schema, will certainly fetch incorrect and erroneous outputs. Reviewing rules in a timely fashion to assess the changes in the source is as important as the initial implementation.
Layer 2: Web crawlers and custom bots for real estate data scraping and multi-source aggregation
Collecting data from sources that do not expose APIs is a major challenge for realtors which they address using Crawlers and custom bots. Leveraging crawlers helps them access diverse data sources at predefined intervals, extract information or records in a specific pattern, and transfer the extracted data downstream to the normalization and validation layers.
Real estate data aggregators use crawlers to serve two of their primary functions simultaneously, one to collect primary listings and property data, second to monitor existing sources for structural changes which disturb the extraction templates.
Custom bots enhance the capacity of crawlers to interact with forms, paginated search results, and visitor-facing portals, where standard crawlers usually fail. Bots play an important role in property data pipelines by handling conversational data collection. It is the collection of user-submitted information through structured question sequences on listing platforms or lead-capture tools.
Key considerations when using custom bots for real estate data scraping and aggregation:
Crawlers operating against MLS data sources must comply with IDX feed agreements and respect rate limits defined in each agreement.
Pipelines should be configured to honor robots.txt directives and implement request throttling that stays within source-defined thresholds.
Non-compliance creates legal exposure and risks source access revocation.
Layer 3: AI and ML in real estate data aggregation for NLP, Computer Vision, and AVM models
Real estate data aggregators should use AI and ML wherever rule based systems reach their limits. Tasks like unstructured text, image-based data, and predictive tasks require pattern recognition across large datasets. Three AI applications that are directly relevant to real estate data aggregation:
Technology
Key Functions
Business Value
NLP for document and listing analysis
Extract structured text data
Identify legal entities (NER)
Validate metadata fields
Parse free-text descriptions
Improve data accuracy
Enable better classification
Reduce manual review effort
Enhance listing completeness
Computer vision for image-based attribute extraction
Analyze satellite imagery
Detect roof and materials
Identify pools, additions
Extract visual property features
Add non-text data insights
Support underwriting decisions
Improve risk assessment
Enable scalable enrichment
AVMs and time-series forecasting
Analyze comparable sales data
Model property value trends
Use ARIMA forecasting models
Process market indicators
Estimate property values faster
Support investment decisions
Improve valuation accuracy
Enable portfolio forecasting
Use of these technologies is creating wonders in unified data ecosystem where structured, enriched, and validated property data is used for advanced analytics. Organizations that adopt AI driven real estate data aggregation will gain a measurable advantage in form of faster insights, improved accuracy, and the ability to scale operations efficiently across diverse real estate markets and data sources.
When Human-in-the-Loop Review Still Beats Automation
Automation nowhere means elimination of human judgement from the property data pipeline. Instead, automation empowers and repositions human judgement. Real estate data aggregators can automate the five tasks we discussed above at the collection, normalization, and validation layers. Data conflicts with legal or financial consequences necessitates human reviews. Here are four specific situations where human review is mandatory:
In case of MLS property data, records that are not compliant to RESO Data Dictionary should not be permitted to get auto published on live feed. They should be pushed to the human review queue. A real estate or property data specialist should verify the record to correct it or remove it. The data pipeline’s role is to flag such records efficiently to reduce the time a data specialist spends in finding problems. What separates your production grade data pipeline from a fragile one is that your pipeline routes edge cases to for human review and does not force an output.
Manual vs Automated: Throughput and Error Rate Comparison
Here’s a comparison between manual and automated approaches across all five tasks that we talked about across the article. Throughput figures show production averages from pipelines processing comparable data volumes and complexity.
Task
Manual Throughput
Automated Throughput
Error Rate (Manual)
Error Rate (Automated)
Property Data Collection
400–600 records/day/FTE
50,000+ records/day
8–12%
<1%
Record Validation
200–300 records/day/FTE
15,000+ records/day
10–15%
<2%
Data Enrichment
150–200 records/day/FTE
10,000+ records/day
12–18%
<2%
Data Cleansing
300–400 records/day/FTE
20,000+ records/day
6–10%
<1%
Document Processing
80–120 documents/day/FTE
1,000+ documents/day
15–20%
<3%
Conclusion
As a real estate data aggregator, you cannot scale manual data processing to meet volumes, update frequency, and accuracy requirements that your clients like real estate portals, lenders, and PropTech platforms now demand. Increasing source diversity in terms of county portals, non-traditional data types, and analytics use cases requiring enriched attributes only widens the gap between manual capacity and market demand.
The five tasks that real estate data aggregators should automate should not be looked at as optimization opportunities. Instead, they should be considered as operational baseline for a production-grade real estate data pipeline. Data collected without automated validation will create a huge, but degradable property database.
At the same time, validating records without enrichment will lead you to thin records. Enriching uncleansed data will produce appended errors. Similarly, processing real estate data documents without automation will create a throughput ceiling, which in-house teams of real estate data aggregators will never be able to clear.
Automating all five tasks, with crawlers, rules-based logic, and AI/ML models will help you create a data pipeline to produce data at the quality and volume that today’s real estate analytics and application use cases require.
FAQs – Frequently Asked Questions
Real estate data aggregation is all about collecting real estate data from diverse sources like MLS feeds, county assessor records, permit registries, and third-party providers. These datasets are then standardized into consistent schema and then maintaining it as an accurate database that works as single source of truth. Real estate data aggregators sell this property data to their clients that include real estate portals, PropTech platforms, lenders, insurers, and investment firms who further use it to glean comprehensive property intelligence across large geographies.
The five tasks that real estate data aggregators should automate includes real estate data collection using crawlers and API connectors. Second task is data validation and verification using rule-based engines and cross-source reconciliation. Third task is data enrichment by appending ownership history, valuation signals, and geospatial attributes. The fourth task is of data cleansing through deduplication, ROT removal, format standardization. And the final task is of document processing using OCR and NLP for extracting data from title deeds, mortgage records, and disclosure forms.
ACM – Automated Valuation Model is a machine learning model that uses comparable sales data, property attributes, and local market indicators, without requiring physical appraisal, to estimate a property’s market value. Investors use AVMs for portfolio valuation, lenders use AVM for mortgage underwriting, and real estate portals use it extensively to estimate prices. The accuracy of AVM models is directly proportionate to the quality, specifically the completeness and freshness, of property database used.
Property data should be validated on ingestion and re-validated on a scheduled cycle, monthly at minimum for owned data, and in real time for externally sourced feeds. Approximately 30% of data in a typical real estate database becomes inaccurate within a year due to ownership transfers, assessed value reassessments, zoning changes, and contact detail updates. Monthly re-validation cycles prevent that decay from reaching downstream users.
Validation confirms that a record is correct, verifying field values against authoritative sources such as county assessor records, USPS AMS, and GIS parcel data. Cleansing corrects or removes records that are duplicate, malformed, outdated, or internally inconsistent. Validation identifies the problem; cleansing resolves it. Both processes are required for a database to support reliable analytics, AVM models, and downstream applications with accuracy SLAs.
Ready to automate your real estate data pipeline, improve operational efficiencies and build confidence in your data.
Snehal Joshi spearheads the business process management vertical at Hitech BPO, an integrated data and digital solutions company. Over the last 20 years, he has successfully built and managed a diverse portfolio spanning more than 40 solutions across data processing management, research and analysis and image intelligence. Snehal drives innovation and digitalization across functions, empowering organizations to unlock and unleash the hidden potential of their data.
What’s next? Message us a brief description of your project. Our experts will review and get back to you within one business day with free consultation for successful implementation.
Disclaimer:
HitechDigital Solutions LLP and Hitech BPO will never ask for money or commission to offer jobs or projects. In the event you are contacted by any person with job offer in our companies, please reach out to us at info@hitechbpo.com
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.