
Top 10 Data Annotation Companies to Outsource

Most businesses aren’t short on data. They’re drowning in unstructured text they can’t use. NLP systems cut through this chaos and text annotation leads the charge.
Table of Contents
In simple terms text annotation transforms raw language into something machines can actually learn from. It’s the grunt work of organizing words so AI doesn’t fail. We use text annotation to turn this massive data mess into a working asset.
The global NLP market clearly shows what’s at stake here. Projections show growth from roughly $24.1 billion in 2023 to an estimated $158.04 billion by 2032. Text annotation is driving this growth.
Here’s the thing – the tools we use daily wouldn’t exist without natural language processing. Chatbots completely fail without it. Virtual assistants become useless. Sentiment analysis stops working. And voice recognition becomes dead. Text annotation makes all of this possible by applying meaningful labels to raw data. It creates the structured foundation machines require.
When NLP systems fail (and we’ve seen plenty crash and burn), the root cause is almost always someone cutting corners on text annotation. You’ve got a clear choice: master these text annotation techniques yourself or hire professional text annotation services. Let’s walk through the 10 techniques you need to know.
Your final model will never beat the data you train it on, and supervised learning requires high quality labeled data. That’s why investing properly in quality annotation isn’t optional.
Text annotators take chaotic, unstructured text and turn it into something a model can train on. Without this, machine learning is impossible. The payoff is a direct, measurable improvement in your model’s accuracy.
But accuracy isn’t everything. These systems need to handle the messy, ambiguous tasks that NLP throws at them. A properly designed text annotation workflow becomes your primary defence against the biases and errors that’ll cost you millions down the line.
Knowing you need annotation is one thing. Doing it right, however, is where teams succeed or fail. Your approach – whether manual, automated, or mixed – makes or breaks the project. Here are the 10 battle-tested text annotation techniques we find ourselves using most often.

Your first pass on any raw text will almost always be Named Entity Recognition (NER). Its sole purpose is finding and tagging concrete things in a document. Names of people, places, companies, dates and monetary values. This is the most basic level of imposing order on unstructured text. It gives your NLP model its first handholds.
The applications are immediate and obvious. Search engines have used NER for years to figure out what a search query is actually about. This improves result relevance. News aggregators use it to automatically sort articles by the people, organizations or locations mentioned.
You’ll also see it constantly in social noise analysis. It tracks mentions of key brands or products. That initial NER pass makes more sophisticated tasks like advanced sentiment analysis capabilities possible down the line.
It’s not magic though. You’ll always fight ambiguity in names and context. The only way to manage this is with solid guidelines, domain experts and rigorous quality checks. The tech keeps getting better but the need for human oversight isn’t going away.
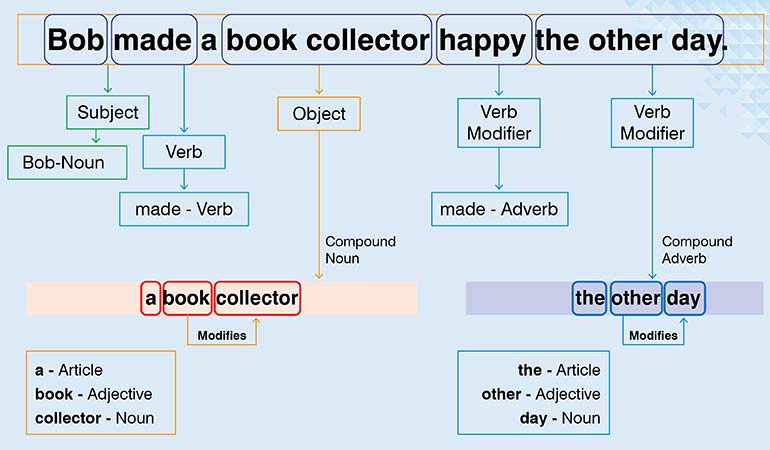
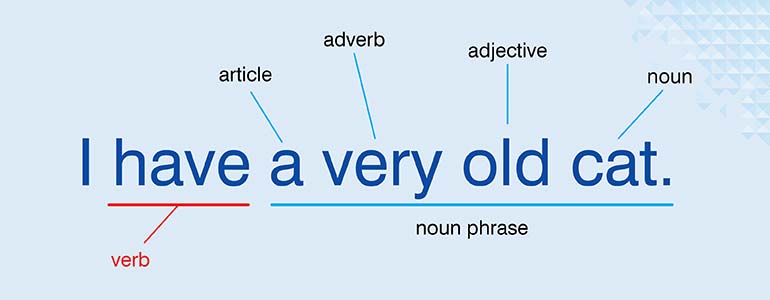
Once you’ve identified entities, you need the grammar holding them together. Part-of-Speech tagging assigns grammatical roles – noun, verb, adjective – to every single word. It’s a fundamental step in bridging the gap between raw words and actual machine comprehension. You’ll use it for almost any kind of deep grammatical or syntactic analysis.
This grammatical data has enormous downstream value. It helps with text classification by providing context. Search becomes more accurate when the context makes it aware of the relationships between words. Of course, spotting grammatical errors are also a task we cannot avoid. And for all these we need that grammatical data.
As context holds the key to proper understanding, a word’s POS tag can completely change how a sentence is interpreted. Take a simple word like ‘bank.’ As a noun, it’s a place you put money. As a verb, it’s an action. A human gets that instantly. A machine needs a POS tag to avoid making a nonsensical mistake. The methods have changed over the years, from old school rule-based systems to the deep learning models we use today.
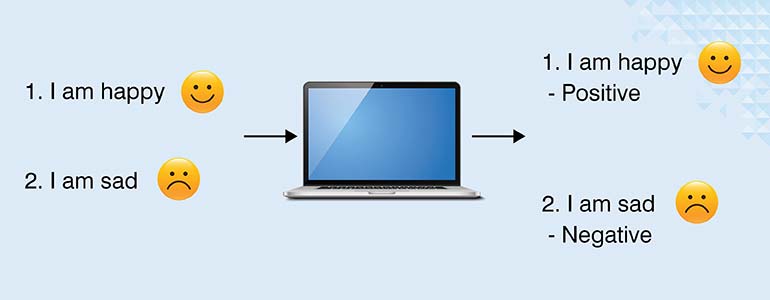
Grammar is one thing but what about emotion? Sentiment annotation decodes the opinions and feelings hidden in text. It’s a labeling process that classifies a statement as positive, negative or neutral. This allows a system to automatically gauge the tone of product reviews, social media posts and the like.
I’ve watched companies use this to track social media reactions before PR problems get out of hand. Customer service departments spot recurring complaints in feedback. Marketing teams monitor how brand perception changes week to week. Before we can improve the customer experience, our machines first need to understand the emotional tone of what’s being said. Sentiment annotation creates the training data to make that possible.
There are a few ways to approach it. Simple category labels to more granular, scale-based systems. Be warned though: this is where you run into some of the toughest problems in NLP. Detecting sarcasm, understanding mixed emotions and interpreting slang are major hurdles that can easily trip up a model.

Text classification is your primary tool for taming chaos. Most organizations deal with a firehose of inbound text. Without automated sorting, they’d collapse. This technique handles sorting and filtering at massive scale. I’ve seen a single well implemented text classification model cut project costs in half for a German company.
Every company has massive amounts of insight buried in its emails, support tickets and social media mentions. But it’s just noise until you classify it. Text classification turns that noise into a signal. Text classification transforms noise into signal, enabling actual decisions. Support tickets get prioritized. Spam gets filtered. Patterns emerge from the data.
This is a broad category. It includes everything from spam detection to sentiment analysis and intent detection. You’ll use a range of methods, from traditional algorithms to big transformer models like BERT and RoBERTa, and deep learning (LSTM, CNN). But you’ll always fight the same classic problems: imbalanced datasets and the complexities of multi label classification.
Sometimes you need to get down to the nuts and bolts of a sentence. Token level tagging labels every single piece, or “token,” to give a machine a highly detailed view of the language. This is non-negotiable for sequence-based tasks where the function of every single word is important. Each token gets categorized, helping models understand meaning and structure simultaneously.
Choose your tokenization strategy carefully. Simple word-level splits work for basic tasks. But most modern NLP models now use subword tokenization. This breaks words into smaller meaningful pieces. The decision always comes down to a trade-off between the needs of your task and your computational budget.
Unlock the full potential of your NLP projects with proven text annotation methods.
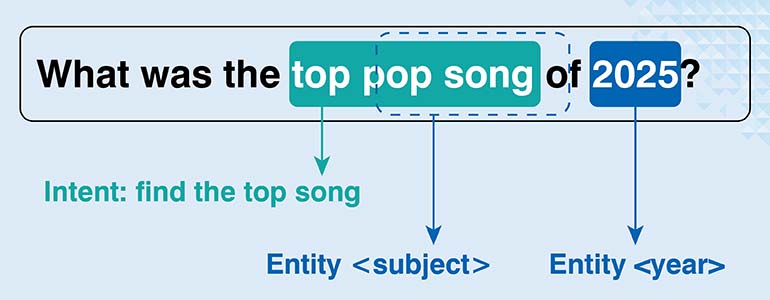
Pay close attention to this one if you’re building any kind of dialogue system. Chatbots or voice assistants. Intent and Slot annotation is the core mechanism that makes them work. It’s a two-part process. First you identify the user’s overall intent. Then you mark the slots, which are the details needed to fulfil that intent. This structure is how a machine breaks down a command into an actionable request.
Here’s a standard example. A user says, “Book a flight from London to Paris for next Monday.” The intent is obviously ‘ticket booking.’ The slots are the pieces of information the system needs to do its job: ‘London,’ ‘Paris’ and ‘next Monday.’ Getting this annotation right is absolutely important in fields like travel and e-commerce. The main challenges are usually handling ambiguous intents or multilingual inputs.
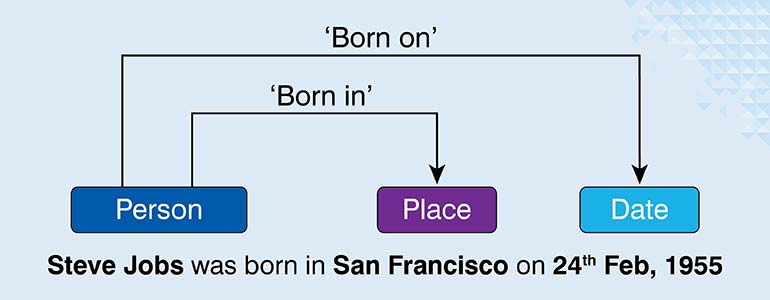
NER tells you what’s in a text. Relation Extraction tells you how those things are connected. After identifying entities, you identify and classify relationships between them. This transforms simple term lists into structured knowledge graphs that understand connections.
These relationships are things like “is the founder of,” “is in” or “works at.” In the sentence “Greg works at the company,” the model extracts a “works at” link from “Greg” to “the company.” That structured data point can then be used in all sorts of applications.
Let’s look at another example: “Penicillin was discovered by Alexander Fleming in 1928.” First NER tags ‘Alexander Fleming’ (person), ‘Penicillin’ (medicine) and ‘1928’ (date). Next, relation extraction builds the connections: Alexander Fleming discovered Penicillin, and it happened in 1928. That becomes a permanent, queryable fact in your knowledge base.

Human language is full of shortcuts. Pronouns, abbreviations and other references. Coreference Resolution Annotation teaches a machine how to keep track of what ‘it,’ ‘she’ or ‘they’ refers to in a text. It’s needed for understanding context and avoiding confusion.
The process finds all the expressions in a text that point to the same real-world entity. Then it links them together. Think of a simple sentence: “Marie went to the store and she bought a pair of shoes.” The system needs to know that ‘Marie’ and ‘she’ are the same person. This annotation creates that link. It’s one of the more complex annotation tasks because language is often naturally ambiguous.
To get to a deep level of understanding, a model needs to see the architectural blueprint of a sentence. It has to look past the words themselves and understand the grammatical structure holding them together.
Syntactic and Dependency Annotation work as a team. Syntactic annotation assigns grammatical roles. Dependency annotation maps relationships, pointing out which words modify the meanings of other words. Together they provide complete structural pictures vital for advanced NLP tasks.
Consider the phrase “the team lead approved the project proposal.” A machine needs to understand the subject verb object relationship to parse it correctly. This kind of structural information is important for machine translation, text summarization and complex question answering systems. In translation for instance, it makes sure the grammar of the output sentence matches the input.

Most serious projects today aren’t just in English. You’ll inevitably run into the need for Multilingual and Cross lingual Annotation. This area of NLP has advanced rapidly to build models that can work across many different languages.
It’s important to know the difference between the two main approaches. Multilingual annotation means labeling data in several different languages. You have to follow the specific rules for each one. Cross lingual annotation is a bit different. It often involves using a well annotated, high resource language to help train a model for a low resource language that lacks good data. Both are key for global applications, but they come with built-in challenges like navigating cultural context and finding qualified expert annotators.
So how do you choose? It almost always comes down to a classic trade-off between speed, cost, quality and specific project goals.
There’s the purely manual route. It’ll give you the highest accuracy but it’s slow and expensive. At the other end is fully automated annotation. It’s fast and can handle huge volumes but you’re going to take a hit on quality. That’s why most teams end up with a semi-automated, human in the loop process. You use tools for the heavy lifting and have humans focus on verification and edge cases.
To pick the right path, we need to think about our project’s scale and complexity.
Achieve consistent results with advanced annotation techniques.
Look, not every organization needs to be in the business of data annotation. For many, the smartest and most cost-effective move is to outsource it to a provider that does this for a living. These firms already have the domain expertise, customized workflows and rigorous quality control processes in place. They’re built to scale up or down as your project requires. And the dedicated support is something you can’t easily replicate in-house.
When you look for a partner, you’ll generally find 2 models: crowdsourcing and dedicated outsourcing. Crowdsourcing can give you scale for massive datasets, but the quality can be unpredictable. If accuracy and reliability are your top priorities, then partnering with a professional third-party firm is the way to go. You pay for their expertise. In return, you get the high-quality data that fits your project’s exact needs.
The flood of unstructured text is only going to get worse. By itself, that data is worthless. The only way for a business to use it is to turn that raw text into structured information. Information that can be analysed to make decisions. That’s the entire point of text annotation, about labeling data so a machine can understand it.
We’ve covered the 10 most common techniques you’ll need. The key is to apply the right one for your project. And if you don’t have the expertise, find someone who does. Keep in mind, techniques and tools are not enough. A well-designed annotation strategy with a human always in the loop is what you need for success.

What’s next? Message us a brief description of your project.
Our experts will review and get back to you within one business day with free consultation for successful implementation.
Disclaimer:
HitechDigital Solutions LLP and Hitech BPO will never ask for money or commission to offer jobs or projects. In the event you are contacted by any person with job offer in our companies, please reach out to us at info@hitechbpo.com


