Data augmentation helps machine learning projects overcome scarce data, reduce overfitting, and improve model accuracy. It saves time, cuts costs, and boosts model performance when applied with the right techniques and expertise.
Machine learning – ML algorithms or Artificial Intelligence – AI models, their performance is only as good as the data they learn from. Accurate and huge datasets are the foundation to robust training datasets but collecting voluminous data is costly, time-consuming and impractical at times.
This is where data augmentation technique proves to be a smart move. By programmatically transforming existing datasets using image rotations, text paraphrasing, or audio pitch shifts; data augmentation enables creation of new, diverse training examples for the ML models without incurring additional cost of data collection.
In this guide, we’ll cover what is data augmentation, its techniques, benefits, challenges, limitations and data augmentation examples. So, get ready to take a deep dive into the world of data augmentation and what it offers to AI and ML models.
What is data augmentation?

Data augmentation is how we artificially generate new data from what we already have. It’s a great way to improve deep learning performance, especially when the original dataset is small or overfitting is a problem. The technique just makes small changes to existing data, which in turn increases the dataset’s size and diversity.
Simple changes like cropping, rotating, flipping images, adding noise to audio or rephrasing text expose models to variations that improve accuracy and helps with overfitting prevention.
To really get it, you need to understand the difference between data augmentation and synthetic data. They both enrich data, but augmentation just modifies existing data while synthetic data creates brand new data points. Think of it this way: augmentation adds variation, but synthetic data generates something entirely new using algorithms.
Use cases include identifying objects from various angles, helping audio models understand language in noisy conditions and aiding motion tracking in video. For tabular data, it helps handle imbalance for better predictions.
Why is data augmentation important
Data augmentation helps AI and ML models to learn and generalize effectively and perform better by making the most of the data we have. Let’s look at a few reasons why it’s so important for driving high performance.
Benefits of data augmentation include
- Addresses data scarcity: Data augmentation helps create a larger and more diverse dataset to train models effectively.
- Improves model performance: By increasing the amount and diversity of training data, data augmentation leads to more accurate and reliable models.
- Reduces overfitting: Augmented data helps the model learn more generalizable features, making it less prone to overfitting the training data.
- Cost effective: Save costs on high-cost data collection methods by reusing existing data.
Data augmentation techniques used for different data types
Data augmentation spans a wide range of data types, and each needs its own specialized techniques. Whether you’re training a convolutional neural network for image recognition, an NLP model for sentiment analysis, or a speech-to-text system, understanding and applying the right data augmentation technique decides whether you will have a fully functional model or a non-performing one.
Let’s look at how we apply augmentation across image, text, audio, video and tabular data.
| Data Type |
Common Techniques |
Example Use Cases |
|
Image
|
Rotation
Flipping
Cropping
Noise Injection
Color Jitter
|
Medical Imaging
- Detect disease markers
- Enhance X-ray clarity
- Train diagnosis models
- Reduce annotation error
Object Detection
- Identify object boundaries
- Classify visual content
- Train surveillance models
- Improve tracking accuracy
|
|
Text
|
Synonym Replacement
Back-Translation
Tokenization
Stopword Removal
Named Entity Recognition
|
Chatbots
- Understand user intent
- Generate smart replies
- Improve language flow
- Handle misspellings
Sentiment Analysis
- Detect emotional tone
- Analyze product reviews
- Flag negative content
- Enhance brand insights
|
|
Audio
|
Noise Addition
Pitch Shifting
Time Stretching
MFCC Extraction
Silence Removal
|
Voice Recognition
- Transcribe spoken words
- Identify speaker voice
- Enable voice commands
- Filter ambient noise
Speech Emotion
- Detect vocal tone
- Recognize emotional cues
- Support therapy tools
- Improve call centers
|
|
Tabular
|
SMOTE
CTGAN
Normalization
One-Hot Encoding
Imputation
|
Fraud Detection
- Identify outliers
- Detect fake patterns
- Train secure models
- Handle missing fields
Customer Segmentation
- Group similar users
- Personalize marketing
- Analyze purchase trends
- Target high-value leads
|
|
Video
|
Frame Sampling
Optical Flow
Temporal Smoothing
Background Subtraction
Object Tracking
|
Surveillance
- Monitor unusual activity
- Track moving objects
- Alert on intrusion
- Improve camera accuracy
Action Recognition
- Recognize human motions
- Classify video segments
- Train sports analytics
- Detect unsafe behavior
|
1. Image data augmentation

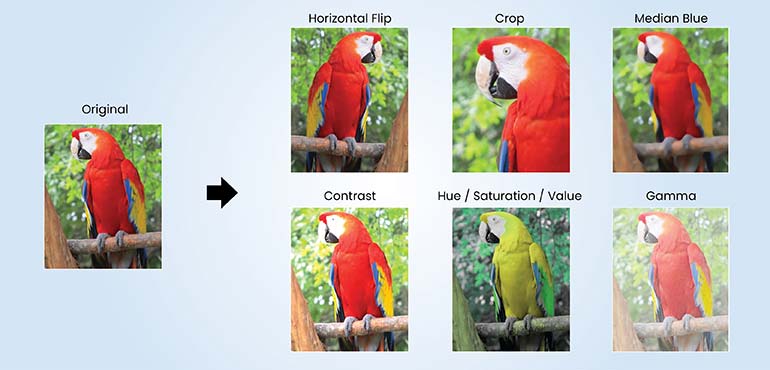
This technique is how we artificially expand the training dataset for computer vision models. We apply different transformations to existing images—like rotations and flips—to create new training data. These changes simulate variations you’d see in real world images, which makes the model more resilient when it’s deployed.
Some of the common techniques for image data augmentation include
- Rotation: Images are rotated by a specified angle (e.g., 90, 180 degrees). This introduces orientation invariance to the model.
- Flipping: Images are flipped horizontally or vertically, creating mirror images.
- Scaling: Changes the size of objects to train scale invariant models.
- Translation: Images are shifted horizontally or vertically, representing changes in object position.
- Shearing: Images are skewed along the x or the y-axis.
- Cropping: A portion of the image is randomly selected and resized.
- Noise Injection: Adds random pixel noise to increase robustness to imperfections.
- Blur/Sharpening: Simulates out of focus or emphasized edges.
- Elastic Transform: Warps images like rubber to simulate realistic deformations.
- Brightness/Contrast Adjustment: Alters exposure to simulate different lighting conditions.
Real-world examples of image data augmentation
Medical imaging: For rare conditions, there aren’t enough labelled images. In these cases, techniques like rotation, scaling and elastic transformations can simulate different scans to help us train more robust diagnostic models.
Autonomous driving: Models often fail because of lighting issues or different angles. In this scenario, techniques like brightness adjustment prepare self-driving models for situations like night driving or glare.
Benefits of image data augmentation
- Improves Model Generalization: Helps models perform well on unseen images by exposing them to varied perspectives.
- Simulates Real-World Variations: Introduces changes in lighting, orientation, and scale to reflect real-life scenarios.
- Reduces Overfitting: Prevents models from memorizing training data by increasing diversity.
- Supports Small Datasets: Artificially expands limited image datasets with synthetic variations.
2. Text data augmentation

This technique creates new text samples by making small changes to existing text. It’s a simple way to improve the diversity and size of a text dataset while keeping the original meaning intact. This is especially helpful for NLP tasks where labelled data is limited because it improves model generalization.
Some of the common techniques for text data augmentation include
- Synonym Replacement: Replace words with their synonyms.
- Random Insertion: Insert a new word randomly into a sentence.
- Random Swap: Swap the positions of two words.
- Random Deletion: Remove words at random with a small probability.
- Back Translation: Translate text to another language and back to generate paraphrases.
- Contextual Augmentation: Use external resources or models to generate variations of the text based on context.
- Paraphrasing with LLMs: Use tools like GPT or T5 to rewrite sentences in different ways.
- Sentence Shuffling: Shuffle sentence order (useful in paragraphs or dialogue).
Real-world examples of text data augmentation
E-commerce product review: Sentiment models can struggle with informal expressions. When that happens, we can substitute a synonym. For example, we might replace ‘a great purchase’ with ‘happy with what I bought’, which is easier for the model to understand.
Virtual assistants: Often, when bots fail to understand a particular expression, back translation or word substitution helps.
News classification: If you have limited labelled articles for each category, you can use sentence shuffling to create new headlines and generate more samples.
Benefits of text data augmentation
- Language Understanding: Boosts model comprehension through synonym replacement, paraphrasing, and back-translation.
- Handles Linguistic Variability: Prepares models for spelling errors, abbreviations, and informal language.
- Improves Multilingual Performance: Strengthens NLP applications across different languages and dialects.
- Boosts Low-Resource Training: Useful in domains or languages with limited labeled text.
3. Audio data augmentation

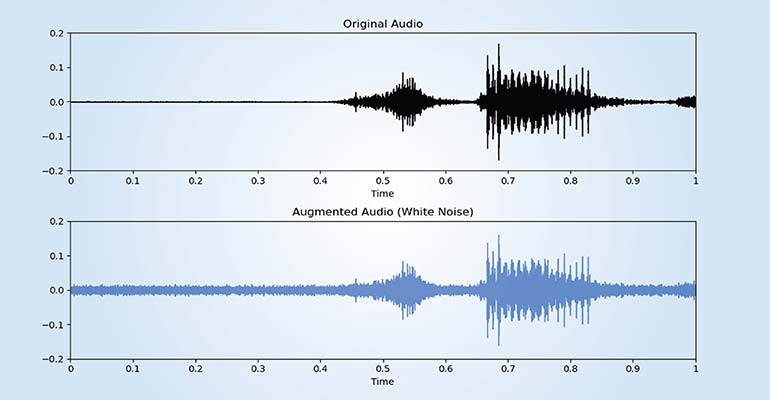
Audio data augmentation is a technique that artificially increases the size and diversity of an audio dataset. We do this by creating modified versions of existing audio samples. This process helps machine learning models generalize better and become more robust to variations in real world audio, helping them do better in noisy environments.
Audio data augmentation techniques
- Time Stretching: Speeds up or slows down audio without altering pitch.
- Pitch Shifting: Raises or lowers pitch while keeping duration the same.
- Background Noise Addition: Adds ambient noise (e.g., street, café) to simulate real world conditions.
- Volume Variation: Randomly increases or decreases the volume.
- Time Shifting: Moves the entire audio waveform forward or backward.
- Reverberation: Simulates echo or different acoustic environments.
- Clipping Distortion: Simulates microphone distortion by clipping signal peaks.
- Dynamic Range Compression: Mimics audio post processing effects (like radio or phone speech).
Real-world examples of audio data augmentation
Voice assistants (e.g., Alexa, Google Assistant): These assistants often struggle to recognize voices in noisy places. So we train the models to work in those environments by adding background noise to the training data.
Speech recognition (ASR Systems): Limited accents or speaking styles in training data can be a problem. Pitch shifting or speed changes can simulate a variety of voices to improve general recognition.
Benefits of audio data augmentation
- Increases Robustness: Helps models perform well in noisy or unpredictable environments.
- Enhances Speaker Diversity: Simulates different voices and accents to improve voice recognition.
- Improves Temporal Tolerance: Time-shifting and stretching train models to handle varied speech rates.
- Compensates for Sparse Audio Data: Augments limited recordings to avoid overfitting.
4. Tabular data augmentation

This technique enhances machine learning models by increasing the size and diversity of tabular datasets. It’s especially useful when we’re dealing with missing values or limited, unbalanced data. It works by generating or modifying structured data to improve model training, which helps in industries like finance, healthcare and fraud detection.
Key techniques used in tabular data augmentation
- SMOTE (Synthetic Minority Oversampling Technique): Creates synthetic data for minority classes.
- GANs (Generative Adversarial Networks): Use generative models to create realistic synthetic records.
- CTGAN (Conditional Tabular GAN): Generates synthetic data while considering the relationships between different features.
- Random Noise Injection: Adds slight variation to numerical features to create new samples.
- Data Interpolation: Generates new rows by averaging or blending features from two existing rows.
- Feature Swapping: Randomly exchanges values between features within the same class.
- Mix up for Tabular Data: Combines pairs of rows and their labels using a weighted average.
Real-world examples of tabular data augmentation
Fraud detection: It’s often hard to get enough data for models to work well because there are so few fraudulent transactions compared to normal ones. This is where SMOTE or GAN based synthesis comes into balance datasets and improve anomaly detection.
Customer churn prediction: If the training data has limited churn cases, it’s tough for the model to spot potential churners. Techniques like SMOTE and feature swapping help train the model to do a better job.
Benefits of tabular data augmentation
- Balances Class Distribution: Techniques like SMOTE help address class imbalance for better model fairness.
- Improves Rare Event Detection: Synthetic samples simulate underrepresented scenarios (e.g., fraud).
- Reduces Impact of Missing Data: Imputation techniques fill gaps for consistent training.
- Enhances Data Privacy: Synthetic data can be used without exposing real user records.
5. Video data augmentation
This technique simulates real world variations by applying transformations to video frames. It works on existing video clips to artificially expand video datasets, which helps improve model performance. By preserving both spatial and temporal information, the technique helps models with jobs like tracking and surveillance.
Key techniques include
- Frame Level Augmentation: Apply image augmentations (e.g., rotation, brightness) to each frame.
- Temporal Cropping: Trim or slide clips to focus on specific segments.
- Frame Skipping: Drop frames randomly to simulate low framerate or signal loss.
- Speed Variation: Speed up or slow down the video to test motion robustness.
- Motion Blur: Simulate camera movement or object motion.
- Reversing: Play video backward to increase data diversity.
- Audio Visual Sync Shifts: Offset audio slightly to improve AV alignment learning.
- GAN based Frame Generation: Generate synthetic transitions or missing frames using deep learning.
Real-world examples of video data augmentation
Video surveillance: Often, low quality or incomplete footage is a challenge for a proper investigation. Synthetic frame generation helps with detection and classification even in poor conditions.
Action recognition: In sports or surveillance, models often struggle to catch speed and partial views. Speed variation, reversing or temporal cropping helps the model learn diverse patterns of human action.
Benefits of Video Data Augmentation
- Improves Generalization and Robustness: It helps in preparing models for real-world video variance and distribution shifts.
- Addresses Data Irregularity: Useful in action recognition and anomaly detection, where real sequences can be rare and highly variable.
- Facilitates Complex Labeling: It gets easier to generate labeled video examples for supervised learning, reducing annotation bottlenecks.
- Enhances Model Performance: The resulting models are more reliable for tasks like tracking or event detection.
Empower your training datasets with expert augmentation.
Real-world data augmentation examples
Data augmentation is a cornerstone technique used by industry leaders to enhance AI performance, reduce bias, and improve model generalization.
- Tesla: Tesla uses image and video augmentation such as camera angle simulation, frame variation, brightness adjustment, and object occlusion in its autonomous driving systems. It helps their self-driving models adapt to diverse road conditions, lighting, and traffic scenarios.
- Amazon: Amazon applies audio augmentation techniques like noise injection and pitch shifting to make Alexa and its voice services more robust across various accents, languages, and background environments.
- Google: In NLP, Google employs text augmentation methods such as back-translation and paraphrasing to train multilingual models, improving tools like Google Translate, Search, and Assistant to understand context and language variations more accurately.
- Meta (Facebook): Use of augmented image and video datasets to train content moderation and facial recognition systems for improved performance of detecting inappropriate content or recognizing users in across settings.
These real-world use cases highlight how strategic data augmentation enables AI systems to generalize better and reduces bias. It also shows how augmentation improves scalability, accuracy, and real-world usability of AI.
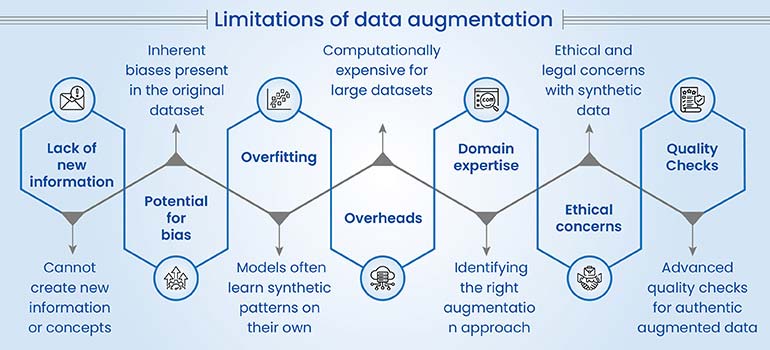
Limitations of data augmentation
Best practices for implementing data augmentation
Using data augmentation isn’t a tough task, but you need to be crystal clear on your needs and follow a streamlined approach. Here are a few tips to help you get accurate results from your data augmentation tasks.
- Understand your data and task: First, examine the nature of your data—is it text, audio or video? Next, identify variations that could happen in the real world. Then you can choose the data augmentation technique that’s best for your project.
- Validate and monitor: Visually check augmented images, listen to augmented audio or review augmented text to make sure they’re realistic and meaningful.
- Evaluate model performance: Compare the performance of your model trained with and without augmentation to assess the effectiveness of your techniques.
- Consider computational cost: Some data augmentation techniques can be computationally expensive, especially when applied to large datasets or during real time training.
- Use efficient implementations: Leverage data augmentation libraries and techniques like GPU acceleration to speed up the augmentation process.
- Balance augmentation intensity: Avoid over-augmenting, as it can distort the data and negatively impact model performance.
- Use techniques like real time augmentation: Apply transformations on the fly during training. This helps you avoid storing augmented data and reduces memory usage.
The future of data augmentation
The future of data augmentation is all about aggressively tackling data limitations to improve model performance. We’re going to see more advanced machine learning techniques, like generative adversarial networks (GANs) and self-supervised learning, creating even more sophisticated and realistic synthetic data.
The rise of generative AI is a game changer. It’s helping create synthetic data and content, which opens new possibilities across all kinds of industries. Its applications are huge, from art and entertainment to healthcare and education.
We’ll see machine learning algorithms automate the data augmentation process itself, learning the best transformations for specific datasets and tasks. This will lead to more effective and diverse augmented data and optimize the whole training process.
Self-supervised learning (SSL) and reinforcement learning (RL) are being integrated more to enhance learning in complex environments, especially where labeled data is hard to come by.
Future research will focus on developing efficient and low power augmentation methods for edge devices and IoT applications, where you just don’t have a lot of computational resources.
Conclusion
So, to wrap things up, it’s clear that efficient machine learning model needs good quality data. That’s non-negotiable, both in quality and quantity. But collecting huge volumes of data costs time and money. Data augmentation is the best way to tackle this challenge, letting us create artificial data from what we already have. You can use different techniques depending on your task to get the best results.
But you need to have a clear understanding of your requirements and the expertise to choose the right technique. If you thoughtfully apply these techniques and follow industry best practices, you can get the full potential out of your models even when data is scarce. And if you don’t have the expertise in-house, you can always get support from data augmentation experts.