How Data Entry Errors Cost Real Estate Companies Millions of Dollars
Snehal Joshi
May 26th, 202616 min read
Real estate data entry errors is one of the major problems the entire industry is facing. These errors can trigger financial losses, compliance risks, and failed transactions. This blog explains common error sources, Zillow’s $569M case study, and ways to improve MLS and property data accuracy.
What turns a minor data mistake into major financial risk in real estate?
It has been observed that over 25% of organizations report losing more than $5 million annually due to poor data quality.
A few companies, like Zillow, make mistakes that result in costly outcomes. Its home-buying program relied on an algorithm that misread market data. The result was a $569 million loss and some layoffs affecting 25% of its workforce. And, it all started with flawed data entering the system.
Zillow is one of the most visible examples, but this is not the only case. Across the real estate industry, these errors quietly lead to compliance issues and a huge revenue loss.
In many cases, businesses deal with the consequences, without tracing the issue back to a simple data entry mistake.
Now, in this article, we’ll look at the kind of real estate data entry errors, where they start, what the cost, and how to reduce them.
What sort of real estate data entry errors are existing?
Real estate systems handle multiple types of data at the same time, such as property details, pricing, legal records, and compliance documents. Each type has its own sort of risks. Below are the 7 most common types of real estate data entry failures.
1. Inaccurate data input
This is the simplest type of error that slips most easily. A wrong digit, a missed decimal, or a typo creates a record that looks fine but harms heavily somewhere in between the real estate data processing strategy.
For example, a property meant to be listed at $3,050,000 is entered as 305,0000. Here, the format looks correct, so the system won’t flag it red, but the listing is drastically underpriced.
These errors usually occur during manual entries, especially when the teams are working quickly or handling high volumes of listings.
2. Transposition errors
Transposition errors occur when numbers or characters are flipped at the time of entry. These errors are easy to miss, because you cannot catch the mistake at a glance.
In practice, sometimes we may write a parcel number 4871-22-083 as 4817-22-083. This small error switch points to a completely different property with a different owner and legal history.
Here, the data is absolutely correct but the way you enter is wrong. Putting correct information in the wrong field or using inconsistent formats can break systems and integrations.
A common scenario is a property’s area is entered as ‘10’ without even specifying the units. Now the question arises – Is it 10 square feet, 10 square meter or 10 acres? The system accepts it, but the data becomes useless for comparison or valuation.
This type of issue often pops up lates when the data is added to some analytics tools or shared across platforms.
4. Unit and representation consistencies
In case various records use different units or formats, the data becomes unreliable. Individually, each entry will look correct, but when put together, they don’t align.
To illustrate, one listing is using square metres and the another is using square feet, while the pricing might appear as “30,000” in one and “30,000 USD” in another.
5. Data misinterpretation
This error depends on the way humans read source material. Even the experienced professionals may misinterpret scanned documents, blurry images or handwritten notes.
Considering this, the letter ‘O’ in a property ID may seem like ‘0’, leading to incorrect records in tax or ownership databases.
It is common in data digitalization projects where paper-based records are being converted into digital formats.
6. Missing information
Missing data creates real gaps in decision making. In real estate, even a single missing field can affect, compliance, valuation or transaction timelines.
For example, a listing goes live without categorizing information, or a lease record is missing shifting dates, may leave buyers, investors, or property managers without critical context.
These gaps often require follow ups, which may hamper the deadlines.
7. Stale data records not updated after changes
Real estate data changes constantly, and in case the data is not synchronized across the systems, inconsistency occurs. Ultimately, it creates multiple records for the same truth.
One of the cases for this issue can be a property sale which is updated in a title system but not updated in the MLS. This is where the ownership details contradict within the different platforms.
This is especially common in MLS data aggregation pipelines where different system update at different schedules.
Now that we’ve seen the most common types of errors, the next question below is obvious.
What we see in practice?
In day-to-day real estate data providers face these errors repeatedly across large datasets and often follow predictable patterns.
From our experience at HitechBPO, the most frequent real estate data entry errors are inaccurate data input, missing inputs and unit inconsistencies.
Most of the issues start with the first point of data capture. This is more likely when the teams work with scanned documents or legacy systems. Most of the issues go filtered at the time of data quality checks.
However, some issues like formatting inconsistencies surface later. They become visible during the standardization phase of data integration or analysis.
These patterns are not random. To fix them, you need to know exactly where in the workflow they enter the system.
Reduce costly real estate data errors with expert-backed accuracy and QA support
Where real estate data errors actually enters the system?
Knowing the types of errors is useful. But, knowing where they come from is what helps you stop them at an early stage.
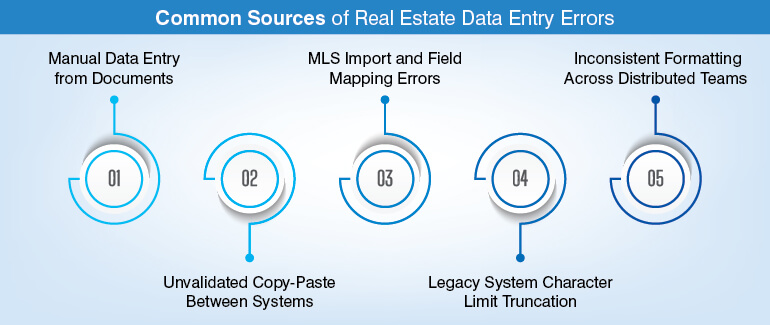
Below are the 5 most common error origination points in real estate data.
1. Manual re-entry from documents
This is the most common source of errors, especially at the character level. Data is mostly extracted from PDFs, scanned copies, or handwritten forms, and entered manually into systems.
In many cases, the same data is typed into a CRM, an MLS platform and a title system. Here each step increases the chance of inconsistencies, typos, and misreads.
2. Copy-paste between systems without validation
Data frequently moves between the platforms through simple copy and paste. Validation is the only problem with it that doesn’t move with it.
A value that works in one system, may not meet in another one where the content is pasted. Without checking the field types, allowed values, or structure, small mistakes turn into larger data integrity issues.
3. MLS import and mapping failures
When data is migrated or aggregated into MLS platforms, mapping errors are common. Fields do not always align the way teams expect.
A price list field in one system, might be mapped incorrectly to a sold price field in another system. These errors can distort datasets.
4. Legacy system field length limit
Most of the older systems follow a strict character limit, so it cuts off the long and fresh data.
A legacy property description that runs 500 characters, may be stored as only the first 255 characters. This record will look perfect at a glance, but inner way the important details may be missed.
5. Disturbed team formatting difference
When data entry is handled across multiple regions, it is obvious to face formatting differences. Each team may follow its own conventions.
Date formats, currency styles, and address structures may vary. Individually, the records may look consistent, but together they become difficult to standardize or integrate.
Now that we know where errors originate, let’s understand what they actually cost once they move through the system.
What is the real cost of real estate data errors?
Once an error enters a production system, it rarely stays in one place. It travels with the data across listings, valuations, legal records, and financial reports.
This leaves a negative impact which builds over time that affects other related processes as the data is reused. A single error may influence multiple decisions, and teams across the lifecycle.
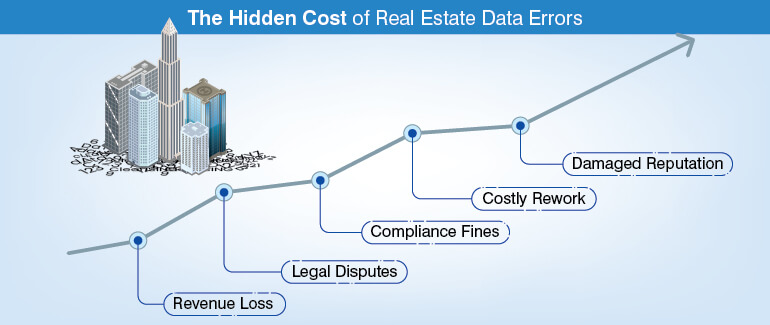
Here’s how these errors show up in 5 key cost areas:
1. Revenue loss from pricing and valuation errors
Pricing errors directly affect financial outcomes. A mistaken footage value or incorrect listing price changes the way a property is positioned in the market.
Data quality research shares a quick report that businesses lose billions each year due to inaccurate data. In real estate, these loses appear in mispriced listing, failed appraisals, and transactions that do not close.
2. Legal fees and transaction disputes
Data errors can quickly escalate into legal problems, especially when the property details do not match actual conditions.
If a buyer discovers discrepancies in square footage or disclosures, the deal may move into dispute. Even a minor error in deed or ownership record can create title complications which may take time and legal efforts to resolve.
3. Regulatory fines and compliance risks
Real Estate data operates within a strict regulatory framework. This includes disclosure requirements, transaction laws and data privacy regulations.
Inaccurate or incomplete data may lead to compliance failures, and some result in financial penalties.
4. Operational cost and rework
Correcting errors after they enter the system is definitely resource intensive. It requires time, coordination and repeated efforts across teams.
The data must be rechecked, corrected and reprocessed. In high volume environments, these inefficiencies add up quickly and impact overall productivity.
5. Reputational damage
Trust plays a major role in real estate transactions. Inaccurate data puts a question mark on buyer’s trust.
A buyer may question the credibility of the listing or the agency, and in many cases the user bounce and do not return. Over time, repeated data issues referrals, brand perception, and long-term business growth. This impact has lasting consequences.
These costs may seem manageable at a glance, but they become much clearer when you look at a real-world example at scale.
The $569 million bet that broke Zillow – a complete case study
The risks we learned about earlier might sound theoretical. But, here’s what it looks like in the real world when the real estate data quality goes wrong.
One of the most well-known examples is Zillow and its failed iBuying program.
What actually happened is..
In 2018, Zillow launched Zillow offers. It was a program designed to buy homes directly from sellers using data and automation. Zestimate was the core of it, being an algorithm built to predict property values and make competitive cash offers.
By 2021 the company had scaled this operation aggressively:
Operating in 25 housing markets
Finalizing the purchase of 27,000 homes
Making quick and automated buying decisions
On paper, it looked like a perfect use case of AI in real estate and big data driven pricing.
But, unfortunately the process was not smooth and as planned. Here’s where it started breaking –
The algorithm struggled to keep up with the rapid market changes and trends. It completely leaned on recent high sale prices and couldn’t adjust for warning signs like:
Rising labor and renovation costs
Supply chain problems
Changing interest rate expectations
The problem was not the ‘incorrect data’. The issue was how the system interpreted and weighted that data. This is the perfect example of data quality issue in real estate where the logic behind the model creates bias.
As a result, Zillow ended up buying homes at prices the market could not support.
Amid the growing excitement around AI-driven decision-making, Amit Seru (a professor of finance at Stanford Graduate School of Business) said:
“There’s a danger [in] getting too carried away by artificial intelligence and machine learning without understanding the underlying economics of the marketplace.”
The Scale of Failure in the Project
This was not a minor bug; it grew up so quickly.
In Q3 2021, Zillow reported a $304 million inventory write down.
By November 2021, it shut down Zillow offers completely.
The total losses reached $569 million
And it was not only about the financial loss:
Around 2000 employees were laid off
Thousands of homes had to be sold off in which many were in loss
What looked like a smart growth strategy, turned into one of the most talked about examples of data-driven decision-making failure in real estate.
What real estate teams can learn from this scenario?
This case was a lesson for everyone working with property data, pricing models, or automated decision systems.
1. Algorithms need the same data validation as humans
Automations are never automatically accurate. Biased or outdated inputs leads to flawed outputs at scale.
Even the reasonable decisions from flawed model can quickly add up to major losses.
This example shows what happens at scale, but the same logic applies in everyday workflows too. Let’s break down how a single error spreads across systems.
How data cascade through MLS & property systems?
There are so many cases similar to Zillow, happening in everyday real estate workflows. Here’s an example:
A property with 1,850 sq ft is mistakenly entered as 1,580 sq ft in the MLS. This one incorrect field doesn’t stay contained. The listing automatically syncs across platforms like Zillow, Redfin, and Realtor.com, all carrying the same wrong number.
In such cases, the buyer’s agent uses this figure for comparative market analysis (CMA). Since the square foot is understated, the valuation comes down and buyer submits a lower offer.
Once the offer is accepted, the deal moves to appraisal and during the process, the appraiser notices the mismatch. Now, the process stalls while the corrected and the appraisal is redone. This generally, delays the transaction by 2-4 weeks and sometimes the buyers cancel the deals.
If the errors aren’t caught before closing, they escalate. It shifts into legal and financial risks which often involves title insurance and disputes over seller disclosures.
By the time these issues are caught, they are already expensive.
Now that you’ve seen how one small mistake can travel and grow, the next step is clear.
How to prevent errors in MLS and real estate data entry?
Once you understand the way errors enter and spread, prevention becomes much more practical. Entry accuracy is not the only goal, but stopping wrong data before it reaches downstream systems.
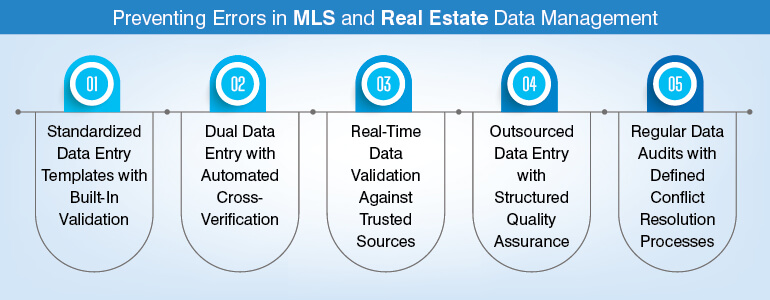
Here are 5 methods that address such failures:
1. Structured data templates with mandatory validation
Free-text fields leave a room for inconsistency. Structured templates enforce rules at the points of entry.
For example, a square foot field should only accept numeric values with defined range and the parcel numbers should follow a fixed format. This can prevent formatting issues and invalid entries before they more into the MLS or other systems.
Aligning these templates with MLS field also avoids mapping errors during data inputs.
2. Double-keying with automated reconciliation
For important data like deed details, closing figures or parcel IDs, accuracy matters more than speed.
In this approach, two operators enter the same data independently, the system compares both entries and flags any mismatch for review before saving the record.
It adds time but reduces errors which is why this is best used selectively for high-impact fields.
3. Real-time validation against authoritative sources
Validating data at the moment of entry prevents wrong records spreading.
Addresses can be checked against the postal databases, and parcel numbers can be cross referenced with county records. This catches invalid or mismatched data at an early stage.
More advanced systems can also flag unusual values, such as price per square foot that falls for outside the local market range. This helps a team catch issues that are not obvious at a first glance.
4. Outsourced data entry with dedicated QA workflows
In house teams often struggle with responsibilities that increases the change of errors by slipping through. A dedicated data entry partner works within defined quality standards including error thresholds, turnaround times, and validate protocols.
They key advantage is separation. The team entering the data is different from the team verifying it.
Strong QA workflows generally include multi-level checks, audit trails, and exception handling, especially for MLS aggregation, title processing, and property database management.
5. Scheduled data audits with conflict resolution protocols
Even accurate data does not stay accurate forever. Properties change, records update, and discrepancies build over time.
Regular audits, monthly for active listings and quarterly for financial data, help identify records that no longer match authoritative sources.
Just as important is having a clear process for resolving conflicts:
Which system is the source of truth for each field
Who is responsible for making corrections
How updates are tracked and verified
Without this structure, even small inconsistencies can persist and eventually create larger issues downstream.
These methods work best when applied consistently. To close things out, let’s tie this back to what it means for your day-to-day operations.
Conclusion
How far would a single incorrect data point travel in your system?
Real estate data entry errors are rarely random. They follow patterns, show up at predictable points, and become more expensive the longer they go unnoticed.
The Zillow case is a high-profile example, but the same issue exists at every level. A small input error, combined with systems that rely on that data, can quietly turn into a much bigger problem.
For businesses handling large volumes of property data, manual checks alone are not sufficient. They take time, increase costs, and still leave gaps.
In these cases, working with a dedicated data entry team that includes built-in quality checks can help maintain accuracy without slowing down operations.
A practical next step is to pick one workflow, such as MLS listings or title records, and map where errors are most likely to enter or go unnoticed. That is usually the fastest way to start improving data quality.
If you want to see this in practice, review Hitech BPO’s real estate data entry services page for a breakdown of their QA process and error-reduction approach.
Frequently asked questions
The most common data entry issue in real estate MLS listings is number mix-ups.
For example, someone types 1,850 sq ft as 1,580, or flips digits in a price or parcel number. Everything still looks correct, so the system doesn’t catch it.
These errors usually slip through and only get noticed later, often when someone double-checks the deal.
The cost of a real estate data entry error usually depends on when the mistake is discovered. If it is caught early, it may only take a few minutes to fix.
However, if the error is found during the appraisal stage, it can delay the closing process by several weeks. In some cases, mistakes identified after closing can even lead to disputes and major financial losses.
There may not be a fixed cost for every error, but one thing is clear: the later the mistake is caught, the more expensive it becomes.
Yes, and it can get serious.
If details like the owner name, parcel number, or legal description are wrong, it can create confusion about who actually owns the property.
This can delay sales or refinancing and may even require legal action to fix. Title insurance helps, but it doesn’t remove the hassle or cost.
Simple way to think about the difference between a transposition error and a transcription error is:
Transposition error = numbers flipped
Example: typing 4871 as 4817
Transcription error = copying the wrong info
For example, entering last year’s value instead of the current one.
Both cause problems, but for different reasons. One is a typing mistake, the other is a copying mistake.
Real estate data errors often happen when there are no proper checks in place. In many outsourced setups, the process is divided between different teams.
One team handles the data entry, while another reviews the work for accuracy.
This creates a built-in quality check instead of relying on a single person to manage everything. Since the data is reviewed by someone else, mistakes are easier to catch before they move further into the process.
Improve MLS and property data accuracy with dedicated real estate data specialists.
Snehal Joshi spearheads the business process management vertical at Hitech BPO, an integrated data and digital solutions company. Over the last 20 years, he has successfully built and managed a diverse portfolio spanning more than 40 solutions across data processing management, research and analysis and image intelligence. Snehal drives innovation and digitalization across functions, empowering organizations to unlock and unleash the hidden potential of their data.
What’s next? Message us a brief description of your project. Our experts will review and get back to you within one business day with free consultation for successful implementation.
Disclaimer:
HitechDigital Solutions LLP and Hitech BPO will never ask for money or commission to offer jobs or projects. In the event you are contacted by any person with job offer in our companies, please reach out to us at info@hitechbpo.com
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.