Data annotation is vital for machine learning and AI, enabling these systems to interpret raw data. Its importance will grow as AI potential is further explored. Let’s understand the facets of data annotation critical to effective machine learning and deep learning algorithms.
From rudimentary notations to sophisticated data-enhancement techniques, data annotation has had a fascinating journey across attempts to structure and extract insights from data. Initiatives like the Semantic Web sought to add metadata to web content so that machines could understand and process information more effectively.
Today, annotation has gained unprecedented importance due to the immense rise of AI and Machine Learning. By 2026, almost every enterprise is expected to incorporate some form of AI into its operations, underscoring the need to devote greater effort toward building capabilities in data annotation.
As AI technologies continue to advance, the demand for high-quality annotated data has soared. The annotation market is expected to grow at an anticipated compound annual growth rate (CAGR) of 26.5% from 2023 to 2030. This growth is projected to culminate in a substantial market value of USD 5,331.0 million by 2030.
Annotation is a broad concept, and several elements and factors define its character. Without looking at these facets of annotation, it is infeasible to serve the needs of your machine learning and deep learning algorithms.
What is data annotation?
There are two important dimensions that help in understanding data annotation. First, its nature, and second, its role. In terms of nature, data annotation is the process of enriching raw data, which comprises affixing labels, tags, or markers to unstructured data. In this way, it provides the ground truth needed to train AI and machine learning models.
Depending on the nature of the data and the objectives of the AI or machine learning project, data annotation can take various forms. So, it’s a broad term that encompasses annotation forms such as image annotation, video annotation, audio annotation, and text annotation.
Data annotation is pivotal in elevating the quality and utility of datasets. The annotated data becomes the bedrock upon which algorithms can train and become more adept at discerning intricate patterns and making precise predictions. Speaking of other ways data annotation helps, it mitigates biases and inaccuracies that may be present in the original raw data. In a way, data annotation is the bridge between raw data and insights essential for sound decision making.
Importance of data annotation
Today, when AI and machine learning are on the agenda of most CEOs and CTOs, data annotation has become a key activity in the entire data processing pipeline that feeds into algorithms. Data annotation drives AI and ML implementation by:
Handling diverse data types
Annotations extend to various types of data, including text, audio, video, and even more complex forms, such as 3D images or medical records. For instance, in medical imaging, annotations are used to identify and classify structures within images, such as tumors, organs, or anomalies.
Training machine learning models
No machine learning models can be trained without data annotation, as models learn from labeled data to perform their function (prediction, classification, etc.). If we are to consider recommendation systems, then user preferences (annotated as likes, dislikes, ratings) train the model to suggest relevant items. Here is a classic case to make you understand this concept better where high-performance image training dataset helped a Swiss food waste management company to build an accurate machine learning model.
Improving model accuracy
Well-annotated data is essential for building precise models, as it reduces errors and thus improves the model’s ability to produce accurate results. Therefore, in autonomous vehicles, accurate annotation of objects in the environment will only ensure that the vehicle is making safe decisions.
Supporting NLP and text analysis
In natural language processing (NLP), text annotation is critical for executing tasks like sentiment analysis, named entity recognition, and part-of-speech tagging. As in sentiment analysis, text samples are annotated with labels indicating positive, negative, or neutral sentiment, which offer input to models to understand and categorize sentiments expressed in text.
Facilitating computer vision (CV)
Object detection, image segmentation, and facial recognition rely heavily on annotated data. Video and image annotations come into the picture to build and provide a training dataset for these CV algorithms. For instance, in facial recognition, annotated images provide key points (eyes, nose, mouth, etc.) that help the model identify and differentiate individuals.
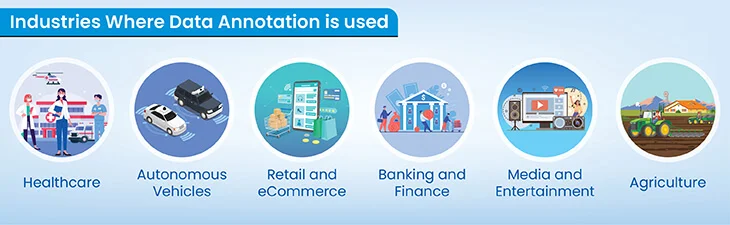
Industries where data annotation is used
The possibilities of using data annotation are growing limitless due to the unprecedented form data is taking. Some of the industries where data annotation has been demonstrating its significance are:

Medical and Healthcare: Data annotation aids in diagnosing diseases and optimizing healthcare delivery through the labeling of medical images and electronic health records. NVIDIA Clara comes forward as a name providing AI-powered healthcare solutions relying on data annotation.
Autonomous Vehicles and Transportation: Annotation is crucial for enabling the safe navigation of autonomous vehicles by identifying objects, lane markings, and road conditions. Waymo and Tesla train their autopilot systems to build autonomous capabilities using data annotation.
eCommerce and Retail: Annotations categorize and attribute products, enhancing search functionality and recommendation systems for online shopping. Amazon, eBay, and Alibaba Group, directly or indirectly, leverage data annotation to perform these functions.
Finance and Banking: Annotations of financial transactions assist in identifying suspicious activities and potential fraud, while sentiment analysis helps in market research. Specializing in fraud detection, Feedzai labels financial transactions to train its predictive models.
Gaming and Entertainment: Annotations support character and object recognition in video games, virtual reality environments, and interactive gaming experiences. As a necessary step, data annotation is proving quite important for companies like Sony and Ubisoft in character animation and offering interactive gaming experiences in VR-based games.
Agriculture: Data annotation aids in crop monitoring and weed detection, helping to assess crop health and predict yield for efficient farming practices. The process has become a part of AI-driven crop monitoring and yield prediction for stalwarts in the field, such as Trimble Agriculture, John Deere and AgShift.
Harness the power of quality data annotation for high performing AI models.
Challenges in data annotation
Annotation has many challenges and is not an easy exercise. When annotators don’t take the right course for addressing a challenge, it leads to the failure of an entire AI and machine learning project. Some challenges typically encountered in the data annotation process are:
- Handling Ambiguity: When data exhibits unclear or multiple interpretations, it confuses annotators in assigning accurate labels, increasing the chances of incorrect assignment. All such ambiguous data elements prove detrimental to the model’s accuracy.
- Avoiding Labelling Imbalance: The implications of imbalanced labeling can be disastrous, as it will result in class imbalance: a classical challenge in AI and machine learning model building. The classes are distributed unevenly, leading to biased models that favor overrepresented categories and potentially hinder the model’s ability to generalize effectively across all classes.
- Managing Annotator Bias: Personal opinions, perspectives, interpretations, or judgments of individuals labeling the data can influence the assigned labels, introducing subjectivity into the annotation process. This can lead to inconsistent or skewed annotations that may affect model performance.
- Realizing Scalability: The appetite of AI and ML models to continuously consume humungous data volumes creates a tough task of scaling the datasets required for the annotation process to operate with the required efficiency.
- Maintaining Consistency: As data continues to flow in, the annotation process must exhibit accuracy and generate sustainable results. The issue occurs when data arrives in the pipeline in unprecedented forms and there’s no extra time to execute the task.
- Optimizing Cost and Time: As a resource-intensive operation, annotation can be expensive and time-consuming, creating pressure on project budgets. Also, as businesses might be keen on achieving results in a decided timeframe, disturbance in the ideal process flow will affect timelines.
- Handling Privacy Concerns: Any loophole in privacy policies pose the risk of data leakage. Weak data protection and the absence of audit processes will make the data vulnerable to unauthorized use and breaches.
Types of data annotation
| Data Annotation Type |
What does it do |
| Text Annotation |
Description
Adding labels or tags to textual data for the purpose of training machine learning models. Important for categorizing or tagging segments of text to execute tasks like sentiment analysis and named entity recognition.
|
| Image Annotation |
Description
Marking and labeling objects or regions in images to train machine learning algorithms in recognizing and understanding visual elements. Used in tasks such as object detection, image segmentation and image classification.
|
| Audio Annotation |
Description
Labeling or transcribing audio data to train models in tasks such as speech recognition, sentiment analysis, or any application where understanding spoken language is important.
|
| Video Annotation |
Description
Annotating frames or segments in a video to identify and track objects or actions, enabling machine learning applications like action recognition, object tracking, and more.
|
| Audio-to-Text Annotation |
Description
Converting spoken language into written text to train models for tasks such as transcription services, voice assistants, and any application that requires the conversion of speech to text.
|
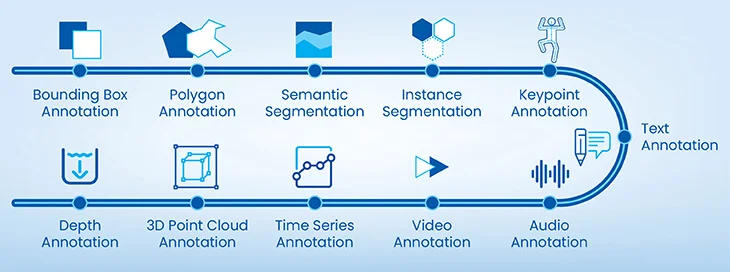
Techniques used in annotation

The efficiency of annotation implementation rests on the technique(s) implemented for a given annotation project. From among the techniques mentioned below, annotators select those that best suit their project.
- Bounding Box Annotation: The most basic technique involves drawing rectangles around objects in an image to indicate their location.
- Polygon Annotation: A bit similar to bounding boxes, but here annotators draw irregular shapes around objects.
- Semantic Segmentation: This assigns a class label to every pixel in an image, providing a detailed understanding of object boundaries.
- Instance Segmentation: It is somewhat similar to semantic segmentation but distinguishes between individual instances of the same class.
- Keypoint Annotation: It identifies specific points of interest on objects, such as the location of joints on a person’s body.
- Text Annotation: Highlights or tags specific text in documents for tasks like Named Entity Recognition or Natural Language Processing (NLP). A lot of AI and ML companies use BERT to significantly reduce the time required for entity annotation.
- Audio Annotation: Labels audio segments for tasks like transcribing speech or identifying sounds.
- Video Annotation: Identifies and labels desired sections of images such as objects or actions within a video, often enabling frame-by-frame analysis. There have been instances of live traffic video stream annotation used by data analytics company for road planning and traffic management.
- Time Series Annotation: This technique labels data points in a time series, which seamlessly improves the accuracy of predictive analytics algorithms.
- 3D Point Cloud Annotation: This is a specialized annotation technique that labels individual points in a 3D space, often used in applications such as autonomous driving.
- Depth Annotation: Another specialized annotation technique, it assigns depth values to pixels in images, which is important for 3D reconstruction.
Struggling with complexities of data annotation? Turn challenges into triumphs.
A range of tools are available for performing annotation, and annotators always choose those that best fit a given project. Some of the widely used tools annotators commonly use are:
- Labelbox: Labelbox is a popular cloud-based platform that offers a range of annotation tools, including bounding boxes, polygons, key points, and more. It supports collaboration, versioning and integration with popular machine learning frameworks.
- Amazon SageMaker Ground Truth: This is a fully managed data labeling service provided by Amazon Web Services (AWS). It provides a range of annotation options and supports both automated and human review workflows.
- Scale AI: Scale AI offers a variety of annotation services and tools, including bounding boxes, polygons, semantic segmentation, and more. It’s known for its high-quality annotations and has been used by many companies to train their models.
- Supervisely: Supervisely is an open-source platform for computer vision tasks, including annotation. It supports various types of annotations and has features for collaboration, team management and model deployment.
- VGG Image Annotator (VIA): VIA is an open-source image annotation tool that is simple to use and can be run in a web browser. It supports different types of annotations, such as bounding boxes, polygons, and points.
- LabelMe: LabelMe is another open-source tool for annotating images. It’s widely used for object detection, instance segmentation, and other computer vision tasks.
- CVAT (Computer Vision Annotation Tool): CVAT is a free, open-source, web-based tool for annotating images and videos. It supports object detection, image segmentation, and video annotation.
- RectLabel: This is a macOS application for labeling images and videos for computer vision projects. It’s particularly popular for annotating bounding boxes.
- Dataturks: Dataturks is a free and open-source platform for data labeling. It provides a user-friendly interface for annotating images, text, and more.
- IBM Watson Studio: IBM’s Watson Studio offers a suite of tools for data science and machine learning, including a data annotation tool for tasks like object detection, image segmentation, and text classification.
Data annotation best practices
Following established guidelines ensures that annotations are consistent and accurate across the dataset. By assimilating the following best practices in your data annotation process, you will preserve the quality of data and bring out the best outcomes from AI and ML models.
- Always clearly defined guidelines provide annotators with specific instructions, reducing ambiguity and ensuring consistent labeling across the dataset.
- Annotators should be trained and updated regularly on domain knowledge and annotation techniques to maintain accuracy and consistency in labeling.
- Continuously review and refine annotations, allowing for feedback loops and improvements in dataset quality over time.
- Implement mechanisms to check and validate annotations, including spot checks, inter-annotator agreement, and feedback loops, to maintain high-quality data.
- Organize labels hierarchically to capture nuanced relationships, enabling more granular analysis and facilitating model training.
- Clearly define and address potential sources of confusion or ambiguity in the annotation process to prevent inconsistent labeling.
- Ensure that datasets represent a balanced distribution of classes or categories to prevent biases and improve model generalization.
- Establish protocols for annotators to handle cases where there’s uncertainty, providing clear instructions on how to make informed decisions.
- Define guidelines for annotating rare or unusual instances that may not fit standard categories, ensuring comprehensive coverage of the dataset.
- Establish a feedback mechanism where annotators can communicate challenges, seek clarifications, and suggest improvements to enhance the overall quality of the annotation process.
A case in point
We accelerated data annotation timelines and significantly improved the AI model performance of a German construction technology company. Our client is from the real estate sector and sought to capture, validate, and verify information from multi-lingual online publications. Our data annotation teams completed the project in record time, within budget, while enhancing outcomes.
Data Annotation Process workflow
The data annotation pipeline, apart from preparing the data to suit the algorithmic needs, also extends to algorithmic execution, as it determines model accuracy. We examine each step that forms a part of this workflow.

- Data Collection: Though not directly linked to annotation, data collection is the primary step in which the data annotation pipeline is actually triggered. The data can come in various forms, such as images, text, audio, or any other relevant format, building a representative dataset relevant to the task.
- Annotation Guidelines: Develop clear instructions and guidelines for annotators, specifying how to label different elements within the data. They serve as a standardized framework to ensure consistency in the annotations.
- Annotation Tool Selection: Annotators go through the technical and business requirements of the project to identify the capabilities that annotation tools should offer. Based on the analysis, annotators will build a repository of the best tools.
- Annotation Process: The actual process of annotating data starts here. Annotators assign specific data samples or segments to annotators. They label or tag the data using suitable techniques, depending on the data type.
- Quality Control: Annotators implement checks to evaluate the accuracy and consistency of annotations at regular intervals. They regulate quality by reviewing a portion of the annotated data and providing feedback.
- Iterative Refinement:Based on the performance of the model, feedback received, or evolving requirements, annotations and guidelines may need to be refined. This step might require revisiting previous stages to make necessary adjustments for improved results.
- Integration with Model Training: The annotated data is fed into the training dataset for the machine learning model. This step is executed only when all data elements are annotated and are ready to build a dataset. Machine learning engineers would then examine the accuracy offered by annotated data. Correctly annotated data will give highly accurate outcomes in machine learning models, and vice versa.
- Feedback Loop: Machine learning engineers will offer their feedback to annotators for ongoing clarifications, addressing questions and improving the annotation process
- Scale and Repeat: As required, the annotation team will scale up the annotation process to include larger datasets or expand it to different data types. Then, they would repeat the workflow as needed for continued model improvement.
Onboard a tool after evaluating it against the following points. If it meets each criterion, then you can successfully start implementing.
- Identify the type of data to be annotated (text, images, audio, video, etc.).
- Determine the level of complexity needed for annotations (basic tagging, object detection, sentiment analysis, etc.).
- Consider the scale of the project and evaluate whether it is small-scale or large-scale, as this influences the choice of tools (simple vs. automated).
- Take into account the expertise of annotators; user-friendly interfaces are important for those with limited technical knowledge.
- Check if the tool integrates smoothly with existing data management, machine learning pipelines, and version control systems.
- Assess the cost of the tool and choose between open-source options or commercial solutions based on project requirements and budget.
- Look for robust documentation, forums, and customer support channels to assist in case of challenges during the annotation process.
Human annotators and how their expertise helps
Human annotators are essential in refining data for machine learning models. Their expertise guarantees precise and relevant annotations. Proficient annotators contribute domain insight, nuanced judgment, and contextual understanding, which are important for the model’s proficiency. Therefore, despite the rise of use of automation in annotation, human annotators must be present in the loop.
Humans possess the ability to comprehend subtleties, cultural context, and ambiguous language, which are crucial for tasks like sentiment analysis or complex categorization. Moreover, human annotators can adapt swiftly to novel data, while automated systems struggle with unforeseen variations. Ethical considerations, such as sensitive content, also necessitate human judgment.
Don’t forget, that the quality of the training dataset you use for your ML models determine its performance. Leveraging some of the most effective ways to label data can get you high-quality training data. It ultimately helps your AI/ML models to make precise decisions that empower you to grow profitably.
How data annotation is undergoing changes
The arrival of new concepts is shaping data annotation, signifying a shift towards more sophisticated applications. Some of the trends bringing about change are:
- Automated Annotation: The integration of machine learning and AI algorithms for automated data labeling is on the rise, reducing manual labor and increasing efficiency.
- Explainable AI: Data annotators are now focusing on creating annotations that facilitate understanding and explanation of the AI system’s behavior. This trend addresses the growing need for trustworthy and accountable AI.
- Multi-Modal Data Annotation: Annotating multiple modes, such as text and images, is gaining importance for applications, such as natural language understanding and computer vision.
- Federated Learning: The need for annotating data locally and securely without centralizing is rising. This approach is essential to preserve privacy and address concerns about centralized data storage.
- Ethical AI Labeling: There’s a growing emphasis on ethical data annotation practices to avoid biases and harmful consequences in AI applications.
Conclusion
To sum up, data annotation is a critical component in the field of machine learning, enabling AI systems to understand and interpret raw data. It involves the process of labeling or tagging data, which can be in various forms, such as text, images, or audio, to make it meaningful for AI models.
Various tools and strategies can be employed for data annotation, each with specific use cases and potential future directions. And their complexity underline the need for expertise in this area, whether it’s through professional services or a thorough understandin of the best practices in the industry. As we continue to explore the potential of AI, the role and significance of data annotation will without doubt continue to grow and take center stage in strategies for ML model development.