Accurate data annotation for ML projects is critical for developing efficient models. Key strategies include refining annotation schemas, prioritizing quality control, addressing bias, optimizing workflows, and leveraging automation. These improve model performance by increasing accuracy, efficiency and ethical considerations in carrying out data annotation.
High-quality, precisely labelled data serves as the foundation for successful machine learning models. Data annotation for ML projects provides the ground truth for these models to learn from. The clearer the labels, the better the algorithm can learn and perform its intended tasks.
To put the importance of data annotation in perspective, consider that the global data annotation tools market is projected to reach $3.4 billion by 2028. And this doesn’t even consider the hundreds of data annotation teams, training operations, development projects, and the massive amount of capital that is invested in data annotation for AI and ML.
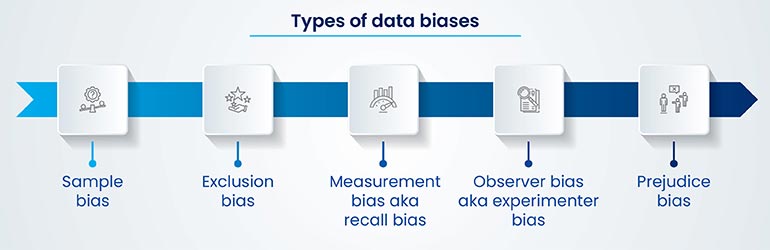
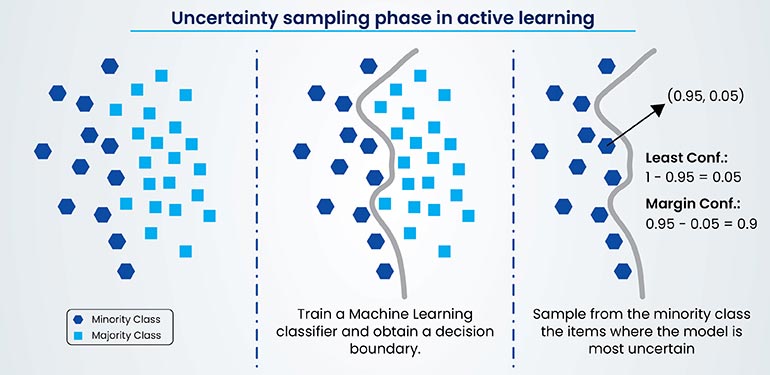
However, in annotation projects, the challenge lies in ensuring label quality. This is handled through effective data labeling strategies such as refining annotation schemas, implementing quality control, addressing bias, leveraging automation for scaling the process and optimizing data annotation workflow management.
These tactics and techniques enhance the accuracy and efficiency of your data annotation process, leading to AI applications that can withstand the stress of performing in live environments.
Understanding Data Annotation for Machine Learning
Data annotation involves labeling raw data to provide context and meaning, enabling algorithms to learn and make accurate predictions. A well-defined workflow is crucial for efficient and accurate annotation.
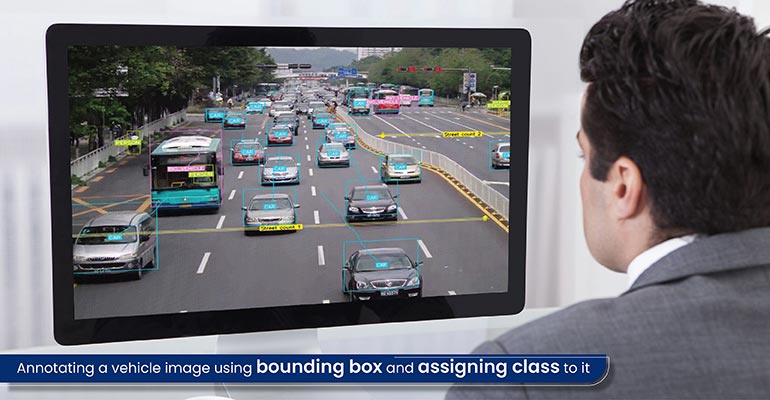
The following are considered key steps in any machine learning data annotation project: