Accurately annotated datasets are critical for your ML models.
Download our article on how to use BERT to improve quality of entity annotation for ML models.
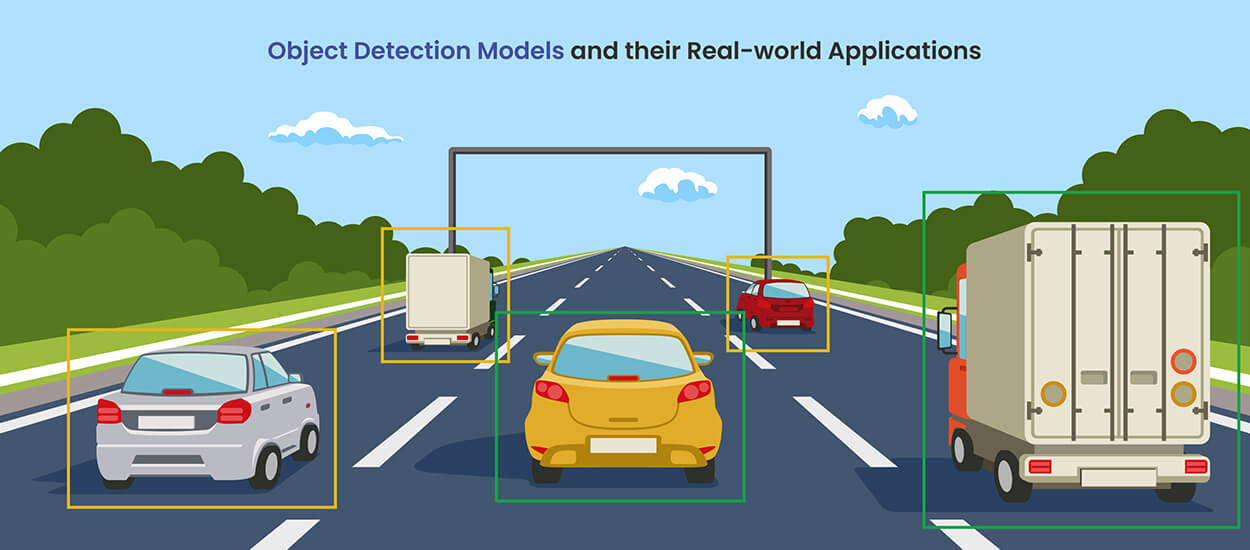
Object detection is at the forefront of innovation, revolutionizing AI and machine learning use. Explore object detection architectures like YOLO and Cascade R-CNN, known for their speed and precision, and discover the benefits and real-world applications of object detection in computer vision.
Table of Contents
Object detection, the process of identifying and locating objects within images or videos, is central to many modern applications. Yet, the complexity and diversity of visual data make accurate object detection a complex task.
Object detection systems go further than simple image classification by recognizing objects like cars, pedestrians, and cyclists. Each box will represent an entity, including cars, pedestrians, and cyclists, as highlighted by the system. Sometimes, understanding object positioning is as important as identifying them.
Artificial Intelligence (AI) and Machine Learning (ML) has supercharged the capabilities of object detection systems. Advanced algorithms, powered by deep learning, can now detect objects with astonishing accuracy, even in cluttered scenes or low-light conditions.
This technological leap has opened up a plethora of applications:
The automation brought about by these deep-learning based object detection systems not only speeds up processes but also minimizes human error, leading to more reliable outcomes. Object detection has grown from rudimentary edge detection algorithms to sophisticated deep learning models.
Here’s a consolidated overview of object detection challenges and the corresponding solutions offered by various models:
Challenge: Object detection requires both classifying objects and pinpointing their exact locations, adding complexity to the detection process.
Solution:
Challenge: Detection algorithms must be swift, especially for real-time applications like video processing.
Solution:
Challenge: Objects in images can appear in various sizes and shapes, making detection challenging.
Solution:
Challenge: Limited annotated data for object detection poses a challenge in training robust models.
Solution:
Challenge: Most images have a few main objects against a larger background, leading to a class imbalance where the background dominates.
Solution:
By understanding and addressing these challenges, the AI/ML community is continually refining object detection techniques, making them more efficient and versatile for a range of applications.

Accurately annotated datasets are critical for your ML models.
Download our article on how to use BERT to improve quality of entity annotation for ML models.
If you’re exploring the world of computer vision, you might be wondering: why should you opt for the best object detection models and the most specific ones? Let’s focus on the reasons.
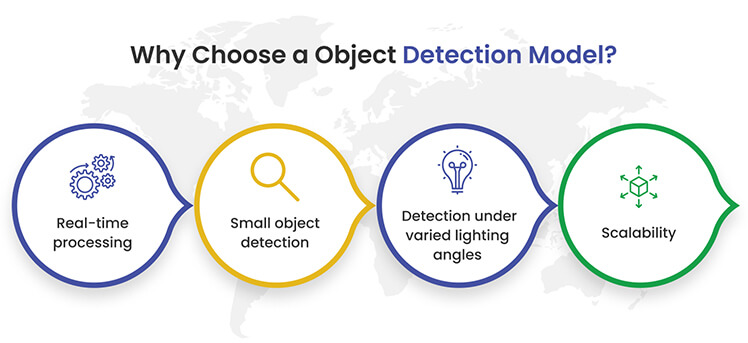
Facilitates real-time processing: In the past, many models struggled with processing images in real-time. But with the advancements in technology, today’s object detection models can swiftly process images without sacrificing accuracy. It’s like upgrading from a slow, buffering video to a smooth, high-definition stream.
Detects small or overlapping objects: Modern models have refined their capabilities. They can now accurately detect even the smallest or overlapping objects in an image. Think of the new object detection models as magnifying glasses that can spot the tiniest details.
Detection under varied lighting angles: Lighting can often pose challenges in detection. However, current object detection models are robust. They can effectively detect objects under varied lighting conditions and from multiple angles, ensuring consistent performance.
Scalability: As your data or project grows, you need an accurate object detection model that can keep up. Thanks to innovative architectures, today’s object detection models can handle increased loads seamlessly, ensuring they scale with your needs.
Curious about which object detection models are leading the charge? Check out the next section right away.
Choosing the right object detection model can be a daunting task. Let’s introduce you to different object detection models of 2026 right here, with different model architectures, advantages, applications and USPs:
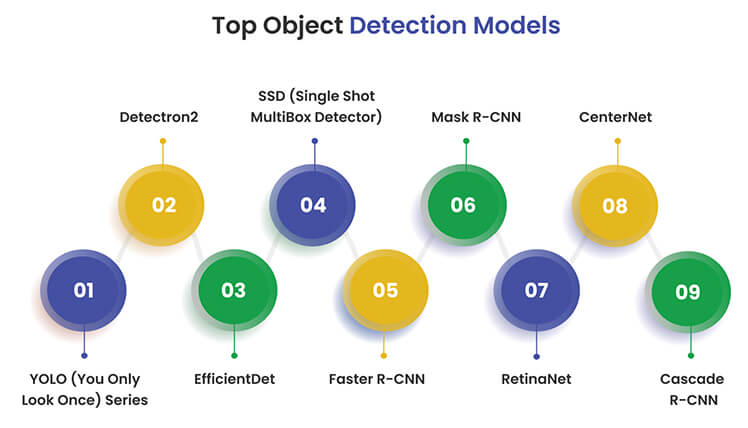
Architecture: YOLO’s architecture is inherently different from the region’s proposal-based methods. Instead of proposing potential object locations and then classifying them, YOLO performs both tasks simultaneously. This concurrent approach is what gives YOLO its name and its speed.
Analysis: Its standout feature is its speed. YOLO can process images in real-time, making it one of the fastest object detection models available. However, this design also means that YOLO might struggle with small objects or objects that are close together, as they might fall into the same grid cell.
Accuracy Stats: In industry benchmarks, YOLOv3, one version of YOLO, achieved a mean average precision (mAP) of 57.9% on the COCO dataset. It runs in 22 ms at 28.2 mAP, featuring accuracy standards similar to SSD but almost three times faster. When compared to other real-time models, YOLO’s accuracy is often superior. For instance, in traffic management systems, we have reported YOLO to achieve top-1 accuracy of 76.5% and a top-5 accuracy of 93.3% in vehicle detection, even in challenging lighting and weather conditions.
Applications:
USP: YOLO’s unique selling proposition is its unparalleled speed without a significant compromise on accuracy. While many models excel in either speed or precision, YOLO strikes a balance, making it apt for real-world scenarios where both are essential. Its ability to process images in real-time, combined with its respectable accuracy, positions YOLO as a frontrunner in the object detection domain.
Architecture: Detectron2 is the next-generation library developed by Facebook AI Research, succeeding Detectron and maskrcnn-benchmark. Built on the PyTorch framework, it offers a modular library rich with a variety of pre-trained models. Detectron2 provides state-of-the-art detection and segmentation algorithms, supporting numerous computer vision research projects and production applications.
Analysis: Detectron2 is not just an incremental improvement over its predecessors, but a complete overhaul. It introduces new capabilities such as panoptic segmentation, Densepose, Cascade R-CNN, PointRend, DeepLab, ViTDet, MViTv2, and more. The library is both a research tool and a production-ready system. Its modular nature allows for easy customization, making it a preferred choice for researchers and developers alike.
Accuracy Stats: Detectron2’s Model Zoo showcases a plethora of models with their respective performance metrics on benchmark datasets, like COCO. For instance, models like Cascade R-CNN achieve impressive mAP scores, indicating their effectiveness in object detection tasks.
Applications:
USP: Detectron2’s unique selling proposition lies in its flexibility and comprehensive feature set. It serves as a playground for researchers, allowing them to experiment with innovative algorithms. Moreover, its modular design ensures that it’s tailored to specific needs, making it a go-to choice for both research and real-world applications.
Architecture: EfficientDet is an innovative object detection model that emphasizes efficiency without compromising on performance. It’s built on the foundation of compound scaling – a method that uniformly scales the resolution, depth, and width of the network. This ensures that the model remains balanced and optimized across various device capabilities. One of the architectural innovations in EfficientDet is the introduction of a weighted bi-directional feature pyramid network (BiFPN). This BiFPN facilitates easy and rapid multiscale feature fusion, enhancing the model’s ability to detect objects of varying sizes.
Analysis: The BiFPN allows for faster feature fusion across different scales. Additionally, the compound scaling method ensures that all components of the model (backbone, feature network, and prediction networks) scale uniformly, maintaining a harmonious balance.
Accuracy Stats: EfficientDet has set new benchmarks in terms of efficiency and performance. For instance, the EfficientDet-D7 variant achieves a state-of-the-art 55.1 AP (Average Precision) on the COCO test-dev dataset. What’s even more impressive is that it achieves this with 77M parameters and 410B FLOPs. This makes it 4x to 9x smaller and uses 13x to 42x fewer FLOPs compared to other leading detectors, showcasing its superior efficiency.
Applications:
USP: EfficientDet’s standout feature is its ability to provide robust performance without being resource intensive. Its name is a testament to its design philosophy – efficiency at the forefront. EfficientDet has established itself as a top pick for object detection tasks in real-world scenarios with limited resources by achieving a perfect balance between speed and accuracy.
Architecture: SSD, or Single Shot MultiBox Detector, is a revolutionary object detection model that operates using a single deep neural network. Unlike two-stage detectors that first generate object proposals and then classify them, SSD does both in one go. It predicts multiple bounding boxes per grid cell and assigns class probabilities to each box. This streamlined approach ensures a single pass image processing, making it highly efficient.
Analysis: The model discretizes the output space of bounding boxes into a set of default boxes with varying aspect ratios and scales for each feature map location. The model’s design guarantees efficient detection of objects with different sizes and shapes.. Integrating predictions from multiple feature maps with different resolutions further enhances the model’s ability to handle objects of various sizes.
Accuracy stats: SSD has set impressive benchmarks in terms of speed and accuracy. SSD achieves a mean average precision (mAP) of 72.1% on the PASCAL VOC2007 test with an input size of 300×300, while operating at 58 FPS on a Nvidia Titan X, setting benchmarks in terms of speed and accuracy.
Applications:
USP: SSD’s unique selling proposition lies in its ability to provide real-time object detection without compromising on accuracy. Its single-pass approach, combined with its capability to detect objects of varying sizes, positions SSD as a top choice for real-time object detection tasks.
Architecture: Faster R-CNN is a pivotal advancement in the realm of object detection. Building upon the foundation of the traditional R-CNN, it incorporates a Region Proposal Network (RPN) that swiftly identifies regions of interest in an image. This integration allows Faster R-CNN to generate high-quality region proposals, which are then passed on to the detection network for object classification.
Analysis: The introduction of RPN is a significant leap as it shares full-image convolutional features with the detection network, enabling nearly cost-free region proposals. This synergy between RPN and the detection network ensures that Faster R-CNN can pinpoint and classify objects in an image with remarkable efficiency.
Accuracy Stats: Faster R-CNN has set impressive benchmarks in the object detection domain. For the deep VGG-16 model, the detection system operates at a frame rate of 5fps on a GPU. Moreover, it achieves state-of-the-art object detection accuracy on benchmark datasets like PASCAL VOC 2007, 2012, and MS COCO with only 300 proposals per image. This performance showcases its prowess in delivering both speed and accuracy.
Applications:
USP: The unique selling proposition of Faster R-CNN lies in its harmonious blend of speed and accuracy. By integrating RPN, it not only accelerates the object detection process but also ensures that the detections are precise and reliable. This balance positions Faster R-CNN as a top-tier model in the object detection landscape.
Architecture: Mask R-CNN is a natural evolution of Faster R-CNN, designed to go beyond just object detection. While Faster R-CNN focuses on bounding box predictions, Mask R-CNN introduces an additional branch dedicated to predicting segmentation masks for each Region of Interest (RoI). This added functionality allows Mask R-CNN to provide pixel-wise segmentation of objects, offering a more detailed representation of detected objects.
Analysis: Mask R-CNN efficiently detects objects in images while simultaneously generating high-quality segmentation masks for each instance. By adding a branch for predicting object masks in parallel with the existing bounding box recognition branch, Mask R-CNN offers a more granular level of object detection.
Accuracy Stats: Mask R-CNN has showcased impressive results across various benchmarks. On the COCO suite of challenges, it has demonstrated top results in all three tracks, including instance segmentation, bounding-box object detection, and person key point detection. Notably, without any additional tweaks, Mask R-CNN outperforms all existing single-model entries on every task, even surpassing the COCO 2016 challenge winners.
Applications:
USP: The unique selling proposition of Mask R-CNN lies in its ability to merge object detection with pixel-wise segmentation. While traditional models might detect an object and provide a bounding box, Mask R-CNN goes a step further, offering a detailed mask that outlines the object’s shape, providing richer and more detailed results.
Architecture: RetinaNet is an innovative object detection model that builds upon the principles of Faster R-CNN. What sets it apart is its integration of a feature pyramid network on a foundational backbone, allowing it to process images at multiple scales simultaneously. But the real significant change is its focal loss function, designed to address the class imbalance problem that often plagues object detection tasks.
Analysis: One of the primary challenges in object detection is the extreme class imbalance between foreground (objects) and background. Traditional cross-entropy loss often struggles in such scenarios, giving undue importance to easy-to-classify negatives. The focal loss function reshapes the loss that it down-weights easy examples and focuses on the hard ones, ensuring that the model learns more effectively.
Accuracy: EfficientDet, YOLOv4, and other models have surpassed the performance of RetinaNet on the COCO dataset. However, RetinaNet’s design and the focal loss function it introduced have had a lasting impact on the field.
Advantages: RetinaNet’s focal loss function is its crown jewel, adeptly addressing the class imbalance issue. Active 1: RetinaNet’s focal loss function ensures that the model is trained more effectively by adeptly addressing the class imbalance issue. It gives more importance to hard-to-detect objects and less importance to clear negatives. This results in a detector that can spot objects of varying sizes, from large vehicles to tiny defects, with equal proficiency.
Applications:
USP: RetinaNet’s unique selling proposition is its ability to detect both large and small objects with equal proficiency. Introducing the focal loss function ensures that the model doesn’t get overwhelmed by easy negatives, allowing it to focus on truly challenging detections. This ensures comprehensive object detection, making RetinaNet a top choice for applications where detail and accuracy are paramount.
Architecture: CenterNet stands distinctively apart from traditional object detection models. Instead of the conventional bounding box approach, CenterNet identifies objects by pinpointing their central points. Following this, the model predicts the dimensions of the object, offering a direct and efficient detection method.
Analysis: The innovation behind CenterNet is its departure from bounding boxes, focusing instead on the central points of objects. This methodology not only simplifies the detection process, but also enhances its accuracy. By eliminating the need for multiple bounding box proposals, CenterNet provides a more streamlined approach to object detection.
Accuracy Stats: CenterNet was rigorously tested, and it showcased exemplary performance. On the BDD dataset, a benchmark for driving scene object detection, CenterNet-Auto has outperformed the original CenterNet in terms of both speed and accuracy. CenterNet-Auto achieved an accuracy of 55.6% on the BDD dataset. The model operates at a speed of 30 FPS, ensuring real-time object detection, which is crucial for autonomous driving scenarios.
Applications:
USP: CenterNet’s hallmark is its innovative approach to object detection. By focusing on central points and predicting object dimensions, it reduces complexities inherent in traditional models. This simplicity, combined with its precision, positions CenterNet as a unique model in the object detection landscape.
Architecture: Cascade R-CNN is a multi-stage object detection model that iteratively refines object proposals across several stages. This architecture addresses the paradox of high-quality detection, which arises due to the commonly used intersection over the union (IoU) threshold of 0.5, leading to noisy detections, and the degradation of detection performance at larger thresholds.
Analysis: The model addresses two primary challenges: over-fitting due to diminishing positive samples at larger thresholds and the mismatch in quality between detector and test hypotheses during inference. To tackle these issues, Cascade R-CNN employs a sequence of detectors trained with increasing IoU thresholds. Each detector training involves the output of the previous one, ensuring a consistently positive training set size and minimizing over-fitting.
Accuracy Stats: Cascade R-CNN has demonstrated exemplary performance across various benchmarks. On the COCO dataset, it achieves state-of-the-art results, outperforming even the COCO 2016 challenge winners. The model also showcases significant improvements in high-quality detection across various object detection datasets, including VOC, KITTI, CityPerson, and WiderFace.
Applications:
USP: What truly sets Cascade R-CNN apart from its peers is its commitment to quality. While many models may prioritize speed or ease of use, Cascade R-CNN’s focus is unwaveringly on delivering the highest quality detections. Its iterative refinement process ensures that each detection is the best possible version, making it an unparalleled choice for applications where precision is non-negotiable.
While these models have certain advantages that gives them an edge over the others for specific applications, organizations often struggle in making the right choice of model. This is the question we deal with next.
Selecting the perfect object detection model for your needs can feel like finding a needle in a haystack. Here’s a roadmap to guide you through this intricate decision-making process:
Every application has its unique demands. For instance, in medical imaging, there’s no room for error, making accuracy paramount. On the other hand, real-time surveillance systems need to make split-second decisions, placing speed at the forefront. It’s essential to strike the right balance based on your specific requirements.
All devices are not created equal. Edge devices, often deployed in remote locations or as part of IoT systems, might have limited computational capabilities. For such scenarios, lightweight models that don’t compromise on performance are the ideal choice.
A one-size-fits-all approach rarely works in the nuanced world of object detection. Depending on the distinctiveness of your project, you might need a model that’s easily trainable on custom datasets, allowing for a more personalized touch.
In today’s data-driven age, the volume of information you handle can snowball. Your chosen model should be like a trusty steed, ready to scale up and handle increased loads without faltering in performance.
Behind every great model lies a vibrant developer and user community. Opting for a model with robust community support can be a significant change. It not only aids in troubleshooting but also opens doors to further customization and enhancements, ensuring you’re always benefitted with the latest advancements.
Confused about choosing the right object detection model?
While these criteria offer a solid foundation, Hitech BPO elevates the decision-making process. We don’t just stop at providing a model; we offer a holistic, tailored solution. With Hitech BPO’s unique HITL (human-in-the-loop) perspective, we ensure that the synergy of human expertise and advanced object detection models delivers unparalleled results for your projects.
Object detection models are already being leveraged in various spheres and domains in varied scenarios, contexts, and purposes. Object detection models are actively transforming various industries. Key sectors where these models are making a significant impact include:
Context: Industrial environments, such as construction sites or manufacturing plants, are rife with potential hazards. These environments need workers to adhere to safety protocols not only for meeting compliance regulations but for their life security.
Model Usage:
Benefits: By leveraging object detection algorithms, industries can significantly reduce workplace accidents, ensuring a safer environment and potentially saving lives.
Context: Self-driving cars are rapidly becoming a reality. But the challenges are immense. The vehicles must make split-second decisions based on surroundings and evade collisions and crashes.
Model Usage:
Benefits: With accurate object detection, autonomous vehicles can navigate complex environments safely, reducing the risk of accidents and making roads safer for everyone.
Context: The retail industry is growing continuously with innovative ways to enhance the customer experience and streamline operations.
Model Usage:
Benefits: Retailers can offer a more personalized shopping experience in their stores, reduce checkout times, and optimize store operations, leading to increased customer satisfaction and sales.
Specific object detection models underpin each of these applications and aligned with the unique needs of the industry. These models, with their underlying architectures, offer a range of advantages that make them ideal for their respective use cases.
Hitech BPO’s commitment to excellence is clear in how we harness the power of object detection models for a myriad of custom applications.
At the heart of Hitech BPO’s success is our unwavering dedication to accuracy. Our team, armed with the latest methodologies, delivers top-tier image annotation services. These annotations serve as the bedrock for powering object detection across diverse sectors, ensuring that the models trained on them are both precise and reliable.
We not only leverage object detection models, but we also recognize the irreplaceable value of human judgment. This understanding has led us to integrate the HITL (human-in-the-loop) approach into our workflows. By doing so, we ensure that every project benefits from the perfect blend of advanced algorithms and human expertise.
Here are some examples of how we make use of diverse object detection models and the HITL approach in custom applications:
We leverage object detection models to analyze in-store foot traffic, product placements, and customer interactions. With the added layer of HITL, we deliver effective annotation solutions to fine-tune insights, ensuring retailers get actionable data to enhance the shopping experience.
Accuracy is paramount in healthcare applications. Our application of object detection models in rendering image annotation services assist radiologists in identifying anomalies in medical scans. The HITL approach ensures that human experts catch and rectify any potential oversight by the model, guaranteeing the highest level of precision.
For city planners, understanding traffic flow and pedestrian movement is crucial. Our application of object detection models, backed by HITL, provide detailed analyses of urban spaces, aiding in creating safer and more efficient urban environments.
Hitech BPO isn’t just about embracing the present; we’re constantly looking ahead. As pioneers in the image and video annotation domain, we’re always reading the pulse of emerging trends. These trends not only shape our current strategies but also pave the way for our future endeavors.
Object detection models encompass a vast ocean of information, with advancements arriving constantly. As we sail forward, expect certain trends to shape the course of this domain, heralding a future filled with transformative applications.

Confluence of AI domains
The future will not favor isolated AI domains but will accommodate synergy-driven AI models and applications. Expect object detection capabilities to be merged with linguistic capabilities of Natural Language Processing (NLP) soon. What this means is that the AI synergy will propel applications such as real-time translation of signboards while you’re navigating foreign lands. ensuring language is no longer a barrier to travel and exploration.
The rise of self-supervised learning
In the world of AI, data is the new gold. But labeled data? That’s sparkling jewels. As acquiring labeled data becomes increasingly challenging and costly, the spotlight will turn to models like DINOv2 that thrive on self-supervised learning. These models, capable of training without explicit labels, promise to revolutionize the object detection landscape.
Edge computing: the new frontier
The Internet of Things (IoT) isn’t just a buzzword; it’s the future. As IoT devices mushroom across the globe, there’s a marked shift in data processing. Instead of centralized cloud-based processing, the focus is shifting towards edge computing. This means they will tailor object detection models to process data right at the source, ensuring real-time insights and reduced latency.
Augmented reality with precision
Augmented Reality (AR) is set to redefine our interaction with the digital world. At the heart of this transformation lies object detection. By accurately identifying and mapping real-world objects, these models will enable AR applications to overlay virtual elements seamlessly, creating immersive and interactive experiences like never before.
The ethical compass of AI
As object detection models become intertwined with our daily lives, there’s a growing emphasis on their ethical dimensions. The future will witness a surge in models designed with privacy at their core, ensuring individuals’ rights are safeguarded. Moreover, there will be a concerted effort to reduce biases, ensuring these models are not just technologically advanced but also socially responsible.
The future of object detection is not just about technological advancements; it’s about creating a harmonious blend of innovation, ethics, and user-centric applications.
The best object detection models are now at the forefront of the AI revolution in computer vision. As we advance, these models will not only become faster and more accurate, but will weave themselves into the very fabric of our daily lives. From smart homes that anticipate our needs to healthcare systems that offer real-time diagnostics, the potential applications are boundless.
For AI and ML companies, this is both an exciting opportunity and a profound responsibility. The challenge lies not just in harnessing the power of object detection, but in doing so ethically and responsibly. As these companies chart their course, one thing is certain: object detection will be a driving force propelling them into a future brimming with possibilities.

What’s next? Message us a brief description of your project.
Our experts will review and get back to you within one business day with free consultation for successful implementation.
Disclaimer:
HitechDigital Solutions LLP and Hitech BPO will never ask for money or commission to offer jobs or projects. In the event you are contacted by any person with job offer in our companies, please reach out to us at info@hitechbpo.com



